2022. 1. 7. 04:00ㆍAI/ML
이 포스트는 허민석님의 유튜브 머신러닝 내용을 정리한 글입니다. 실습 코드는 도서 나의 첫 머신러닝/딥러닝에서 발췌해왔습니다. 실습 코드와 자료는 링크의 Github에서 볼 수 있습니다.
이번 포스트에서는 SVM, 서포트 벡터 머신 알고리즘에 대해 알아보겠습니다. SVM은 kNN, Decision Tree와 마찬가지로 주로 classificaion을 위해 사용되는 알고리즘으로, 이해하기 어렵지 않은 알고리즘에 비해 성능이 매우 우수하여 지도학습 머신러닝 알고리즘으로 자주 사용됩니다. 서포트 벡터 머신은 적은 데이터에 대해서 다른 알고리즘에 비해 높은 정확도를 내며 예측 속도가 빠르고, 뒤에서 알아볼 커널 트릭을 통해 다양한 feature를 갖는 데이터를 분류하기 쉽다는 장점이 있습니다. 그렇다면 SVM 알고리즘은 무엇이고 어떤 동작 원리로 실행되는지 알아보겠습니다.
이해를 돕고자 교재의 서울의 어느 지역이 강북인지, 강남인지를 구분하는 예시를 들어 설명하겠습니다. 우리는 현재 서울에서 용산, 이태원, 한남, 금호, 동작, 반포, 신사, 압구정을 여행했습니다. 아래의 그래프는 X, Y축을 동쪽과 북쪽으로 설정한 다음 강북의 용산, 이태원, 한남, 금호를 O, 강남의 동작, 반포, 신사, 압구정을 X로 표현한 그래프입니다. 만약 우리가 강북과 강남을 구분 지을 수 있는 한강의 위치를 2차원 공간의 선으로 표현할 수 있다면, 새로 여행할 성수동이 강북인지, 강남인지 구분할 수 있을 것입니다. 이때 데이터를 구분하는 선, 여기서는 한강을 곧 SVM의 decision boundary(결정 경계)라고 합니다. 단순히 강북과 강남이 구분되기만 하면 되니, 선으로 표현할 수 있는 한강의 후보는 다양합니다. 아래 그림에서 보라색으로 표시된 한강의 위치 후보1의 선과 위치 후보2의 선 둘 모두 강북과 강남을 구분할 수 있으니, 두 후보 선은 SVM 알고리즘의 decision boundary라고 말할 수 있습니다. 하지만 kNN에서 최적의 k를 찾는 것이 중요한 문제였듯이, SVM에서도 최적의 decision boundary를 찾는 것이 중요합니다. 그렇다면 후보 1과 후보 2 중 더 좋은 decision boundary는 어떤 것 일까요? 후보 1은 decision boundary와 강북, 강남의 데이터 중 가장 가까운 데이터 간의 거리가 후보 2에 비해 넓습니다. 후보 2의 decision boundary는 지금의 데이터에서는 가장 잘 학습된 경계선이지만, 용산에서 조금 내려간 이촌을 자칫 강남 지역으로 잘못 예측하는 등 테스트 및 새로운 데이터에 대해서는 정확도가 낮을 수 있습니다. 따라서 후보 1의 decision boundary가 더 좋다고 볼 수 있습니다.

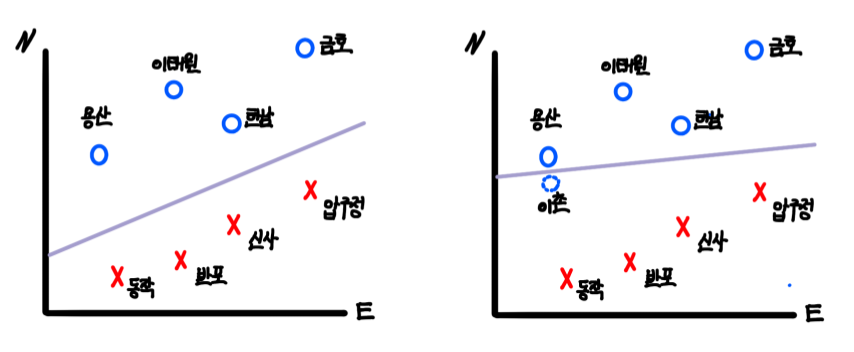
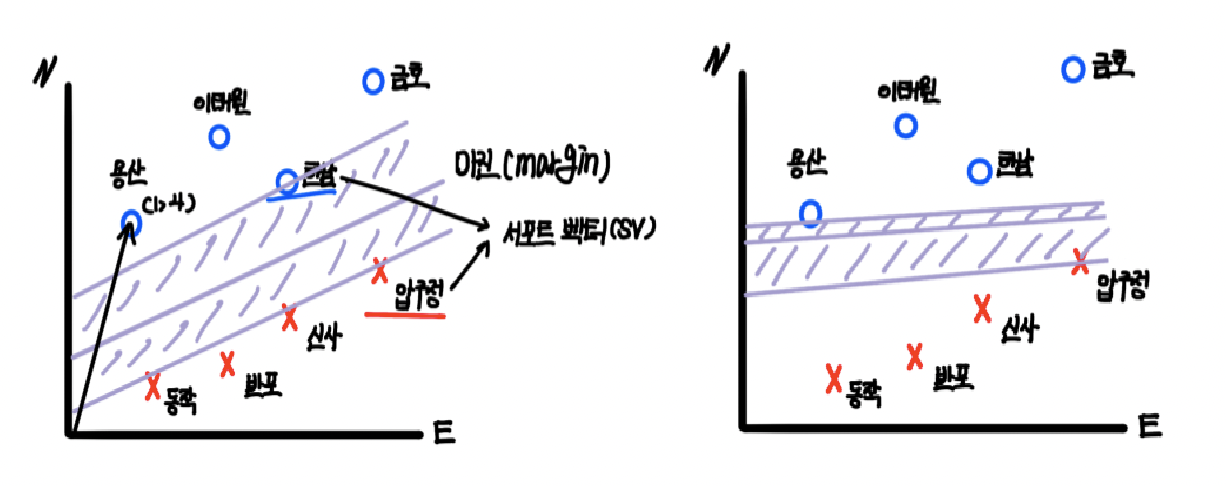
이제 우리는 "SVM은 최적의 decision boundary를 찾으면 새로운 데이터에 대해서도 쉽게 예측할 수 있겠다"는 결론을 낼 수 있습니다. 그렇다면 앞으로 최적의 decision boundary은 어떻게 찾는지, 1차원 공간의 혹은 3차원 그 이상의 다차원 공간의 데이터에 대해서는 어떻게 처리하는지에 대해 알아보겠습니다. 그보다 먼저 SVM에서 2차원 공간의 벡터에 대해 짚고 넘어가겠습니다. 벡터는 크기와 방향을 갖는 선으로, 비록 위의 그래프에서 한남동을 하나의 점으로 표현했지만, 실제로는 서울 최서남단의 (0,0) 지점에서 시작해 (5,5) 지점으로 향하는 벡터입니다. 따라서 이해를 위해 용산을 O, 반포를 X 점으로 표현했지만, 실제로는 (0,0) -> (1,4)의 벡터, (0,0) -> (3,1)의 벡터라고 이해하는 것이 정확합니다. 위에서 후보 1은 decision boundary에서 가장 가까운 한남, 압구정 사이 간격이 넓은 반면 후보 2는 용산, 압구정 사이의 간격이 매우 좁다고 했는데, 이처럼 decision boundary의 최전방 데이터 포인트인 한남과 압구정, 용산과 압구정을 Support Vector라고 하며 Support Vector와 decision boundary 사이의 거리를 margin이라고 합니다. SVM에서는 margin을 최대로 하는 decision boundary를 찾는 것이 목표이며, margin이 클수록 새로운 데이터에 대해서 안정적으로 분류할 가능성이 높습니다.
이제 vector로 표현된 데이터들의 Support Vector를 찾아 margin을 최대로 하는 decision boundary를 설정하는 것이 끝일까요? 사실, 실제 데이터에는 outlier(이상치)들이 존재합니다. 강남과 강북을 구분 짓는 것은 사실 한강 위치 하나의 속성만으로 결정지어도 큰 문제가 없지만, 이전 포스트에서 kNN 알고리즘 실습에서처럼 3점 슛을 많이 득점한 센터 포지션의 농구 선수도, 리바운드를 많이한 슈팅 가드 포지션의 농구 선수도 존재합니다. 그러면 이러한 outlier들에 대해서도 하나 하나 모두 학습하면 되지 않을까요? 이 문제에 대해서는 예전 포스트에서 Cost와 Overfitting, Underfitting에 대해 다룬 적이 있었습니다. 간단히 말하자면, 아래의 오른쪽 그림2과 같이 군집을 벗어난 outlier들에 대해 모두 학습할 경우, Overfitting(과대적합)으로 인해 테스트 및 새로운 데이터에 대해서는 오류를 낼 가능성이 더욱 높아집니다. 오히려 왼쪽 그림1는 outlier를 제외하고보면 margin이 그림 2에 비해 큽니다. 결국 궁극적인 목표는 테스트와 새로운 데이터에 대해 높은 정확도를 보이는 모델을 생성하는 것이기 때문에, 모델 설계 시 학습 데이터에 대해서만 에러가 적게끔 설정하는 것은 좋은 방법이 아닙니다. 그림1에서 X를 O라고 분류하는, 학습 모델의 오류를 허용하기 위해 decision boundary와 margin의 간격을 어느 정도로 할지를 결정하는 cost(비용, C)를 사용합니다. cost는 얼마나 많은 데이터가 다른 클래스에 놓이는 것을(오류) 허용하는지를 결정하는 변수입니다. cost가 낮을수록, margin을 최대로 하고 학습 에러율을 증가하는 방향으로 decision boundary를 설정하는 것이 합리적입니다(soft margin). 반면 cost가 높을수록, margin을 낮추고 학습 에러율을 감소하는 방향으로 decision boundary를 설정하는 것이 바람직합니다(hard margin). 따라서 적절한 cost를 찾아 과소적합과 과대적합을 일어나지 않도록 하며 최적의 decision boundary를 설정하는 것이 중요합니다.
결국 SVM에서 가장 중요한 것은 decision boundary를 찾는 것입니다. 위의 예시에서 2차원 공간에서 decision boundary는 선으로 표현되었습니다. 그렇다면 항상 decision boundary는 1차원 선의 개념일까요? 사실 decision boundary는 (벡터 공간 차원 - 1)차원으로 정해집니다. 2차원 좌표계 공간에서 decision boundary는 1차원 선으로 존재하는 반면, 3차원 공간의 데이터에서 decision boundary는 2차원의 면으로 존재합니다. 이러한 이유로 decision boundary는 때로 hyperplane으로 불리기도 하며 아래의 수식으로 표현할 수 있습니다.
Decision boundary = (Vector Dimension - 1)D
그렇다면 1차원 데이터의 decision boundary는 0차원의 점으로 표현해야 합니다. 하지만 아래 그림에서처럼 직선 상의 O와 X를 구분 짓는 점 형태의 decision boundary를 찾으라고 한다면, 누구도 적절한 정답을 낼 수 없을 것입니다. 어느 지점에 놓아도 학습 모델의 오류가 너무 높아 과소적합이 발생할 것이며 새로운 데이터에 대해서 에러율이 높을 것입니다.
이러한 문제로 인해 SVM에서는 주어진 저차원 벡터 공간의 데이터 벡트들을 고차원 벡터 공간으로 매핑하여 옮긴 다음 decision boundary를 찾는 작업을 진행합니다. 예를 들어, 1차원 선 상의 데이터(x)들을 2차원 데이터로 매핑하면 y축이 생기게 됩니다. y = x^2라는 함수를 통해 1차원 데이터들을 매핑한다면 데이터는 (-2, 4) 등의 2차원 벡터로 표현할 수 있으며, 아래의 그림에서처럼 데이터들을 2차원 좌표계에 그려 적절한한 decision boundary를 찾을 수 있습니다.

물론 한 차원 상위의 2차원 공간에 매핑될 때도 데이터는 벡터의 형태로 매핑되며, 저차원 데이터를 고차원 데이터로 매핑하고자 사용한 y = x^2을 Mapping function(매핑 함수)이라고 합니다. 하지만 실제로 데이터를 고차원의 데이터로 매핑하고자 한다면 데이터의 양이 너무 많아 계산량이 많아지므로 속도가 느려져 사용하는 것에 제한적입니다. 따라서 실제로 데이터를 고차원의 데이터 형태로 매핑하지는 않으며 동일한 효과로 빠른 속도로 decision boundary를 찾는 방법을 고안했으며, 이 방법이 바로 kernel trick(커널 트릭)입니다.
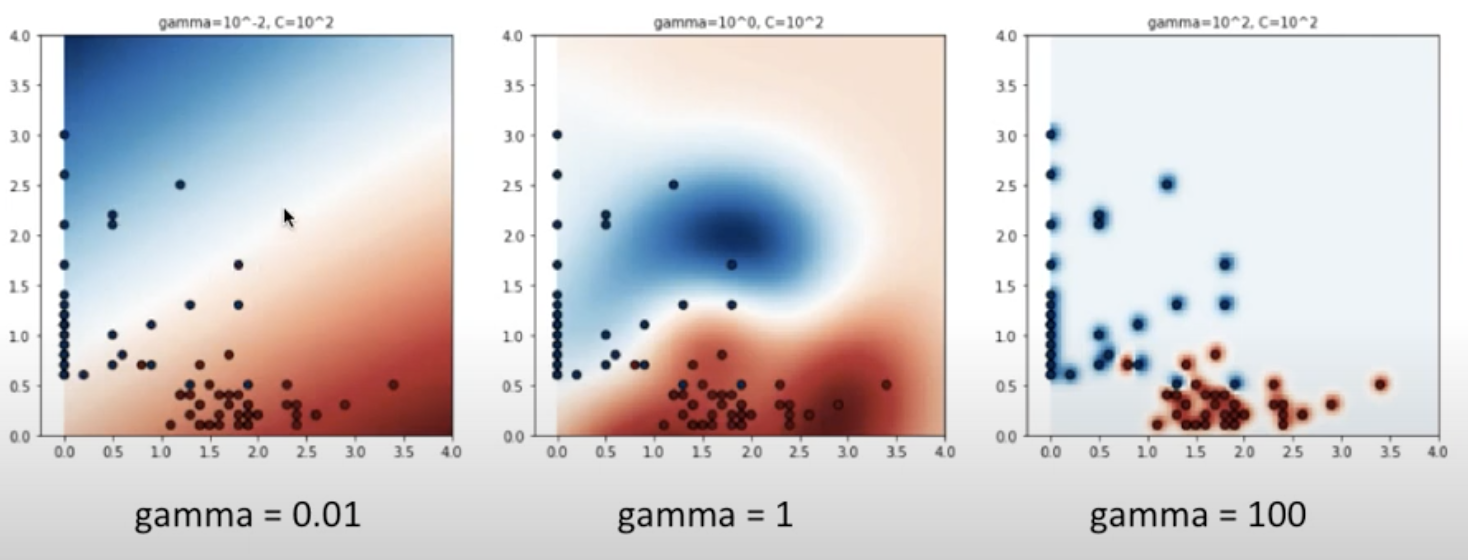
kerenl의 parameter로 위에서 언급한 cost와 gamma를 조절하여 decision boundary의 margin을 조절할 수 있습니다. gamma는 일전에 언급했던 overfitting을 피하고자 Regularization의 cost function에 (lambda)*(∑w^2)를 더해주는 것처럼, kernel에서의 gamma는 데이터 포인트의 영향이 미치는 범위로, decision boundary의 곡률을 조정하는 parameter입니다. gamma가 적을 경우에는 하나 하나의 데이터 포인트가 영향을 끼치는 범위가 넓어지지만, gamma가 높을 경우에는 데이터 포인트가 영향을 끼치는 범위가 좁아집니다. 아래 그림을 보면 gamma = 0.01일 때는 그 범위가 넓어져 파란색 범위와 빨간색 범위가 넓은 범위로 나타나지만, gamma = 100이되면 그 데이터 포인트 바로 주위에만 영향을 끼치게 되어 파란색 범위와 빨간색 범위가 데이터 포인트에 한정적입니다. 따라서 gamma가 커질수록 decision boundary가 학습 데이터에 맞게끔 구부러지는 모습을 보이며, gamma가 작아질수록 decision boudnary가 일반적으로 직선의 모습을 띄게 됩니다. 이는 cost와 마찬가지로 overfitting과 underfitting의 문제를 불러올 수 있으며 따라서 cost와 gamma를 조정하며 overfitting과 underfitting에 대처하여 최적의 decision boundary를 선택하는 것이 중요합니다. 아래의 표는 최적의 cost와 gamma parameter를 찾는 Grid Search의 예시입니다.
| cost \ gamma | 1 | 10 | 100 |
| 1 | 0.7 | 0.8 | 0.7 |
| 10 | 0.8 | 0.8 | 0.9 |
| 100 | 0.6 | 0.8 | 0.8 |
마지막으로 SVM 알고리즘의 장단점을 알아보겠습니다. 먼저, kernel trick을 사용하여 features가 많은 데이터를 분류하는 데에도 강합니다. N-features의 데이터는 N차원 공간의 데이터 포인트 벡터로 표현되고, N+1 차원의 공간에서 hyperplane을 찾아 데이터 분류가 가능하기 때문입니다. 또한 overfitting과 underfitting을 parameter(cost, gamma)를 조절하여 대처할 수 있으며 적은 학습 데이터로 학습 시에도 높은 정확도를 보입니다. 하지만 그만큼 데이터 전처리 과정이 상당히 중요하며 특성이 많아질 수록 데이터와 decision boundary를 시각화하여 표현하는 것이 어렵습니다.
이번 포스트에서는 SVM 알고리즘에 대해 알아보았습니다. 다음 포스트에서는 SVM 알고리즘을 실제로 실습해보며 kNN 알고리즘에서와 같이 2020-21 시즌 농구 선수의 포지션을 SVM 알고리즘을 활용하여 예측해보겠습니다.
'AI > ML' 카테고리의 다른 글
| 머신러닝 모델의 성능을 알아보자 (0) | 2022.01.08 |
|---|---|
| SVM(Support Vector Machine) 실습 - 농구 선수 포지션 예측 (0) | 2022.01.08 |
| kNN(k-Nearest Neighbors) 알고리즘 - 농구선수 포지션 예측(2) (0) | 2022.01.03 |
| kNN(k-Nearest Neighbors) 알고리즘 - 농구선수 포지션 예측(1) (0) | 2022.01.02 |
| Decision Tree + ID3 알고리즘 (0) | 2021.12.24 |