2022. 1. 8. 19:00ㆍAI/ML
이 포스트는 허민석 님의 저서 "나의 첫 머신러닝/딥러닝"의 내용을 정리하였습니다.
저번 포스트에서 우리는 아래와 같이 사이킷런의 classifiaction_report와 accuracy_score를 사용하여 SVM 모델의 정확도를 측정해봤습니다. 정확도(accuracy) 0.95는 한눈에 들어오지만 classification_report에 나오는 precision, recall, f1-score 지표들은 한눈에 들어오지 않아 이해에 어려울 수 있습니다. 이번 포스트에서는 precision, recall, f1-score 등 다양한 머신러닝 모델의 평가 방법을 알아보고, 최종적으로는 아래의 표를 해석해보겠습니다.

시작에 앞서, 이해를 위해 선행되는 5가지에 대해 알아보겠습니다.
1. 혼동 행렬(confusion matrix)
혼동 행렬은 지도 학습으로 훈련된 분류 알고리즘의 성능을 시각적으로 나타낸 표입니다. 행은 예측값을, 열은 실제값을 (혹은 그 반대) 나타내며 예를 들어 손으로 쓴 알파벳을 보여줬을 때 알파벳을 알아맞히는 머신러닝 모델의 혼동 행렬을 보겠습니다. 아래 표의 행은 예측값을, 열은 실제값을 의미합니다.
| 실제 \ 예측 | A | B | C | D |
| A | 9 | 1 | 0 | 0 |
| B | 1 | 15 | 3 | 1 |
| C | 5 | 0 | 24 | 1 |
| D | 0 | 4 | 1 | 15 |
위의 혼동 행렬을 분석해보면, A를 10번 보여줬을 때, 9번은 A로 정확히 예측했으나 1번은 B로 잘못 예측했습니다. B를 20번 보여줬을 때는 15번을 B로 정확히 예측했으며 1번은 A, 3번은 C, 1번은 D로 잘못 예측했습니다. 동일한 방법으로 C, D에 대해서도 분석할 수 있으며, 혼동 행렬을 통해 모델이 B를 C로, C를 A로, D를 B로 잘못 예측하는 빈도가 다소 잦다는 정보를 얻고서 모델의 성능을 높이는 방법을 찾을 수 있습니다.
2. TP (True Positive) - 맞는 실제값을 올바르게 예측한 것
TP는 혼동행렬에서 실제값 A를 A로 정확히 예측한 경우를 말합니다. 위의 혼동 행렬에서 빨간색으로 표시된 대각선이 부분이 TP입니다.
TP는 정답인 예측을 말하며, 이제부터 이해를 위해 실제값을 파란색, 예측값을 빨간색으로 표시하겠습니다.
| 실제 \ 예측 | A | B | C | D |
| A | 9 | 1 | 0 | 0 |
| B | 1 | 15 | 3 | 1 |
| C | 5 | 0 | 24 | 1 |
| D | 0 | 4 | 1 | 15 |
3. TN (True Negative) - 틀린 실제값을 올바르게 예측한 것
TN은 틀린 것을 틀렸다고 올바르게 예측한 것으로, A클래스에 대한 TN은 실제값 A가 아닌 것을 A가 아니라고 올바르게 예측한 경우를 말합니다. A 클래스에 대한 TN은 A가 아닌 클래스들에 대해 A가 아니라고 예측한 값들을 의미하며, 아래 표에서 색깔로 표시된 칸들에 해당합니다. TP와 달리 클래스 별로 TN이 따로 존재합니다.
| 실제 \ 예측 | A | B | C | D |
| A | 9 | 1 | 0 | 0 |
| B | 1 | 15 | 3 | 1 |
| C | 5 | 0 | 24 | 1 |
| D | 0 | 4 | 1 | 15 |
4. FP (False Positive) - 틀린 실제값을 맞다고 잘못 예측한 것
FP는 틀린 것을 맞다고 잘못 예측한 것으로, A 클래스에 대한 FP는 실제값 A가 아닌 것을 A가 맞다고 잘못 예측한 경우입니다. 다시 말해 A클래스의 FP는 A에 대해 A가 아닌 B, C, D를 A로 잘못 예측한 값들입니다.
| 실제 \ 예측 | A | B | C | D |
| A | 9 | 1 | 0 | 0 |
| B | 1 | 15 | 3 | 1 |
| C | 5 | 0 | 24 | 1 |
| D | 0 | 4 | 1 | 15 |
5. FN (False Negative) - 맞는 실제값을 틀렸다고 잘못 예측한 것
FN은 맞는 것을 틀렸다고 잘못 예측한 것으로, A 클래스에 대한 FN은 A라는 실제값을 A가 아니라고 예측한 경우입니다. 아래는 A 클래스의 FN을 표현했으며, TP를 제외한 나머지 값들이 클래스 별 FN에 해당합니다.
| 실제 \ 예측 | A | B | C | D |
| A | 9 | 1 | 0 | 0 |
| B | 1 | 15 | 3 | 1 |
| C | 5 | 0 | 24 | 1 |
| D | 0 | 4 | 1 | 15 |
TP, TN, FP, FN은 많이 헷갈릴 수 있습니다. 따라서 한 클래스를 예로 들며 한 문장으로 정리하며 이해하면, 혼동을 줄일 수 있습니다. 예를 들어 A 클래스에 대해 TP, TN, FP, FN은 순서대로 "A에 대해 A라고 예측", "A가 아닌 것에 대해 A가 아니라고 예측", "A가 아닌 것에 대해 A라고 예측", "A에 대해 A가 아니라고 예측"이라는 한 문장으로 정리할 수 있습니다. 혼동 행렬과 TP, TN, FP, FN에 대해 완벽히 이해되었다면, 이제 모델의 성능을 평가하는 지표에 대해 하나씩 알아보겠습니다.
1. 정확도 (accuracy)
정확도는 보편적으로 사용되는 모델 성능을 평가하는 지표로, 모델이 입력된 데이터에 대해 얼마나 정확히 예측하는지를 나타냅니다. 위의 혼동 행렬에서 보면 A를 A라고 정확히 예측, B를 B라고 정확히 예측하는지 등에 해당하며, 이는 TP로 따라서 정확도는 TP를 전체 셀로 나눈 값입니다.
| 실제 \ 예측 | A | B | C | D |
| A | 9 | 1 | 0 | 0 |
| B | 1 | 15 | 3 | 1 |
| C | 5 | 0 | 24 | 1 |
| D | 0 | 4 | 1 | 15 |
정확도: (9 + 15 + 24 + 15) / 80 = 0.78
2. 정밀도 (precision)
정밀도는 모델의 예측값이 얼마나 정확하게 예측되었는지를 나타내는 지표입니다. 교재의 암환자 예측 모델의 예를 들어 이해해보겠습니다. 아래의 표에서 행으로 나열된 암환자, 일반 환자는 예측값, 열으로 나열된 암환자, 일반 환자는 실제값입니다.
| 실제 \ 예측 | 암환자 | 일반환자 |
| 암환자 | 9 | 1 |
| 일반환자 | 30 | 60 |
암 예측 모델 A의 혼동행렬
| 실제 \ 예측 | 암환자 | 일반환자 |
| 암환자 | 1 | 9 |
| 일반환자 | 20 | 70 |
암 예측 모델 B의 혼동 행렬
예측 모델 A, B 중 어떤 모델이 더 좋은 모델로 볼 수 있을까요? 위에서 알아본 정확도(accuracy)를 지표로 두 모델을 비교해보면, A 모델의 정확도는 (9 + 60) / 100 = 0.69, B 모델의 정확도는 (1 + 70) / 100 = 0.71로 B 모델이 더 좋은 모델으로 판단할 수 있습니다. 하지만 데이터의 특성상, 우리는 단순히 정확도에 중점을 두지 않고 암이라고 예측했을 때, 예측이 더 정확한 모델을 선호할 것입니다. 암이 아님에도 모델이 암으로 예측했다면, 당장 불필요한 치료들을 받아야 하는 위험이 있습니다. 이처럼 정밀도는 예측값이 얼마나 실제값에 정확한지를 나타냅니다. 아래는 정밀도를 구하는 공식이며, 공식에서 TP는 "암환자를 암환자로 정확히 예측한 경우", FP는 "일반 환자를 암환자로 잘못 예측한 경우"에 해당합니다. 실제로 계산한 모델 A의 암환자 정밀도는 9 / (9+30) * 100 = 23%, 모델 B의 암환자 정밀도는 1 / (1+20) * 100 = 4.7%로, 정밀도 측면에서 A가 B에 비해 더 좋은 모델로 볼 수 있습니다.
정밀도(precision) = TP / (TP + FP)
3. 재현율 (recall)
재현율은 실제값 중 모델이 정확히 예측한 값의 비율을 나타내는 지표입니다. 암환자 예측 모델에서 암환자 재현율은 실제 암환자들이 모델에서 암환자로 예측되는 비율입니다. 정밀도와 헷갈릴 수 있는데, 정밀도는 예측값의 시점에서 실제값을, 재현율은 실제값의 시점에서 예측값을 판단한다고 생각하면 이해에 도움이 될 수 있습니다. 따라서 재현율과 정밀도는 서로 Trade-off 되는 성격을 지니며, 아래의 재현율을 구하는 공식에서 TP는 "암환자를 암환자로 정확히 예측한 경우", FN은 "암환자를 일반 환자로 잘못 예측한 경우"에 해당합니다.
| 실제 \ 예측 | 암환자 | 일반환자 |
| 암환자 | 9 | 1 |
| 일반환자 | 30 | 60 |
| 실제 \ 예측 | 암환자 | 일반환자 |
| 암환자 | 1 | 9 |
| 일반환자 | 20 | 70 |
재현율(recall) = TP / (TP + FN)
실제로 계산해보면 모델 A의 암환자 재현율은 9 / (9 + 1) * 100 = 90%, 모델 B의 암환자 재현율은 1 / (1 + 9) * 100 = 10%로, 재현율을 측면에서 A가 B에 비해 더 좋은 모델로 볼 수 있습니다.
4. F1 score
정밀도와 재현율 모두 중요한 수치로 상황에 따라 무엇을 쓸지 고민될 수 있습니다. 데이터에 따라 정밀도를 사용하는 것이 합리적으로 보일 때 재현율을 사용했다면, 위에서 말했듯 둘은 Trade off 되는 특성이 있으므로 자칫 잘못 사용하면 원하는 모델을 선택하지 못할 수 있습니다. 이런 이유로 나온 F1 score는 정밀도와 재현율을 조화 평균 내어 하나의 수치로 나타낸 지표입니다. A, B의 조화 평균의 공식은 2AB / (A+B)이며 아래 그래프의 교차점에 해당합니다.
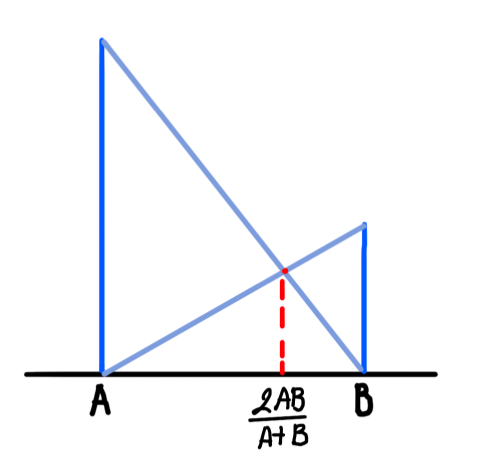
따라서 재현율과 정밀도의 조화 평균인 F1 score의 공식은 아래와 같습니다. F1 score는 정밀도와 재현율의 특징을 모두 포함하므로 정확도와 함께 성능 평가에 많이 사용됩니다. 그렇다면 정확도와 F1 score는 각각 어떤 경우에 자주 사용될까요?
F1 score = 2 * precision * recall / (precision + recall)
먼저 정확도는 데이터 레이블의 분포가 균일할 때 주로 사용합니다. 레이블의 분포가 균일하다면 모든 레이블에 대해 비슷한 성능을 보여주는 것이 보장되므로, 이 때는 정확도를 주로 사용합니다. 하지만 아래의 표에서처럼 레이블이 불균일하게 분포되어 있을 때는 정확도는 왜곡된 성능 평가를 보여줍니다. 이러한 경우에는 F1 score를 사용하여 더 나은 모델을 판단합니다. 아래의 예시를 보겠습니다.
| 모델 1 실제 \ 예측 | A | B | C | D |
| A | 995 | 5 | 0 | 0 |
| B | 8 | 0 | 1 | 1 |
| C | 10 | 0 | 0 | 1 |
| D | 0 | 1 | 9 | 0 |
위의 표의 모델 1은 A 레이블에 대해서는 잘 맞추지만 B, C, D 레이블에 대해서는 하나도 맞추지 못하고 있습니다. 또한 A 레이블에 해당하는 데이터의 비율이 압도적으로 많아, 좋은 모델로 볼 수 없음에도 정확도는 (995 + 0 + 0 + 0) / 1030 * 100 = 96.6%로 매우 높은 수치를 보입니다. 또한 아래 표의 모델 2에서도 비록 예측 수준은 높아졌지만, 여전히 레이블이 데이터 상에서 불균일하게 분포되어 있는 모습을 보입니다. 그렇지만 한 눈에 봐도 모델 1에 비해서는 좋은 모델으로 평가되어야 하지만, 모델 1과 모델 2를 정확도 측면에서만 평가하자면 모델 1의 정확도는 96.6%인 반면, 모델 2의 정확도는 70.5%로 모델 1이 더 좋은 모델로 잘못 판단할 수 있습니다.
| 모델 2 실제 \ 예측 | A | B | C | D |
| A | 700 | 100 | 100 | 100 |
| B | 0 | 9 | 1 | 0 |
| C | 0 | 0 | 9 | 1 |
| D | 0 | 1 | 0 | 9 |
이제 모델 1과 모델 2를 F1 score를 계산해 비교해보겠습니다. 먼저 A, B, C, D의 클래스 별 재현율과 정밀도를 계산하여 표에 추가합니다.
| 모델 1 실제 \ 예측 | A | B | C | D | 재현율(recall) |
| A | 995 | 5 | 0 | 0 | 0.99 |
| B | 8 | 0 | 2 | 2 | 0 |
| C | 10 | 0 | 0 | 1 | 0 |
| D | 0 | 1 | 9 | 0 | 0 |
| 정밀도(precision) | 0.98 | 0 | 0 | 0 |
| 모델 2 실제 \ 예측 | A | B | C | D | 재현율(recall) |
| A | 700 | 100 | 100 | 100 | 0.7 |
| B | 0 | 9 | 1 | 0 | 0.9 |
| C | 0 | 0 | 9 | 1 | 0.9 |
| D | 0 | 1 | 0 | 9 | 0.9 |
| 정밀도(precision) | 1 | 0.08 | 0.08 | 0.08 |
먼저 모델 1의 평균 정밀도는 (0.98 + 0 + 0 + 0) / 4 = 0.245, 평균 재현율은 (0.99 + 0 + 0 + 0) / 4 = 0.2475로, F1 score를 구하면 2 * 0.245 + 0.2475 / (0.245 + 0.2475) = 0.246입니다. 반면 모델 2의 평균 정밀도는 (1 + 0.08 + 0.08 + 0.08) / 4 = 0.31, 평균 재현율은 (0.7 + 0.9 + 0.9 + 0.9) / 4 = 0.85로, F1 score는 2 * 0.31 * 0.85 / (0.31 + 0.85) = 0.454로 모델 1에 비해 큽니다. 따라서 레이블이 정확도의 측면이 아닌 F1 score로 두 모델을 비교했을 때, 원하는 "모델 2가 모델 1에 비해 더 좋은 모델입니다"라는 결론을 얻을 수 있습니다.
이제 이전 포스트의 2020-21 시즌 NBA 농구선수들의 포지션 예측 SVM 모델을 사이킷런의 classification_report를 사용하여 평가한 결과표를 해석해보겠습니다.
먼저 표에서 우리는 레이블 별 precision(정밀도), recall(재현율)의 결괏값, 이를 조화 평균 낸 f1-score를 확인할 수 있습니다. support는 레이블의 실제 샘플의 수를 알려줍니다. 이전 포스트에서 실제값과 SVM 모델의 예측값을 비교한 아래의 데이터 프레임을 보면,
실제 레이블을 담은 grount_truth에는 C(센터) 레이블이 7개, SG(슈팅 가드) 레이블이 13개의 샘플이 있음을 알 수 있습니다.

정확도 accuracy는 0.95를 확인하고 보니, 처음 보는 macro avg와 weighted avg가 있습니다. 순서대로 macro avg는 샘플 레이블 수의 불균형을 무시한 채 클래스 별 동일한 가중치를 두고서 평균을 낸 지표입니다. recall의 macro avg를 확인하면 샘플 레이블 수 support가 C와 SG가 서로 다름에도, 두 클래스에 동일한 가중치를 두어 두 값을 단순 평균 낸 0.96(recall macro avg = (1.00 + 0.92) / 2)이 나옵니다. 반면 weighted avg는 샘플 레이블 수의 불균형을 고려하여 표본의 수를 가중치로 두어 평균 낸 값입니다. 동일하게 recall의 weighted avg를 확인하면, 샘플 레이블의 수 7, 13을 각각의 precision에 곱한 다음 더하여 전체 레이블 수 20으로 나눠줍니다.(recall weighted avg = (1.00 * 7 + 0.92 * 13) / 20) 결과적으로 macro avg는 샘플 레이블의 수를 무시한 채 모든 클래스 별 동일한 가중치 1을 두고 계산하기 때문에 소수 샘플 클래스의 성능이 낮을 때 그 영향력이 커 전체 평균값이 낮아지는 모습을 보이지만, weighted avg는 샘플 레이블 수를 가중치로 두어 계산하기 때문에 소수 샘플 클래스의 영향력이 작아 전체 값에 미미한 영향을 미치는 모습을 보입니다.
'AI > ML' 카테고리의 다른 글
| Decision Tree 실습 - 지니 계수 및 서울 지역 다중 분류 (2) (0) | 2022.01.19 |
|---|---|
| Decision Tree 실습 - 지니 계수 및 서울 지역 다중 분류 (1) (0) | 2022.01.19 |
| SVM(Support Vector Machine) 실습 - 농구 선수 포지션 예측 (0) | 2022.01.08 |
| SVM(Support Vector Machine) (0) | 2022.01.07 |
| kNN(k-Nearest Neighbors) 알고리즘 - 농구선수 포지션 예측(2) (0) | 2022.01.03 |