2022. 1. 8. 00:00ㆍAI/ML
이 포스트는 허민석님의 유튜브 머신러닝 내용을 정리한 글입니다. 실습 코드는 도서 나의 첫 머신러닝/딥러닝에서 발췌해왔습니다. 실습 코드와 자료는 링크의 Github에서 볼 수 있습니다.
이번 포스트는 SVM(Support Vector Machine) 모델로 kNN 알고리즘에서처럼 2020-21 시즌 NBA 농구 선수의 포지션을 예측해보겠습니다. 데이터 크롤링과 EDA 과정은 이전 포스트에서 다뤘으므로, 모델을 생성하는 작업부터 시작하겠습니다. 먼저 필요한 라이브러리들을 임포트한 다음, 2020-21 NBA 농구 선수들의 데이터를 읽어 들여 판다스 데이터 프레임의 형태로 생성합니다. kNN EDA 과정에서 찾은 분별력이 떨어지는 특징들을 데이터 프레임에서 제거한 다음 전체 데이터를 학습 데이터와 테스트 데이터로 분리했습니다.

이번 SVM 실습에서는 RBF 커널을 사용하며 먼저 두 parameter(C, gamma)의 최적값을 찾아야 합니다. C와 gamma에 대해 다시 짚고 넘어가겠습니다. 비용(C)은 얼마나 많은 데이터가 다른 클래스(오류)에 놓이는 것을 허용하는지를 조정하는 변수로 비용이 낮을수록 margin을 최대한 높이고 train error를 증가하는 방향으로 decision boundary를 설정하며, 반대로 비용이 높을수록 margin을 줄이고 train error를 감소하는 방향으로 decision boundary를 설정합니다. 비용을 낮추면 margin이 높아져 다소 범용적인 decision bounary를 갖는다는 장점이 있지만 과소적합을 유의해야 하며, 반대로 비용을 높이면 margin이 낮아져 학습 데이터에 대해 높은 정확도를 보이지만 과대적합의 위험이 있습니다. gamma는 kernel의 표준 편차를 조절하는 변수로, gamma가 작을수록 데이터 포인트가 decision boundary에 미치는 영향이 커져 decision boundary가 완만한 기울기를 보이며 반대로 gamma가 클수록 데이터 포인트의 영향이 작아져 decision boundary가 작아지며 구부러집니다. 비용과 마찬가지로 gamma가 작을수록 과소적합의, gamma가 클수록 과대적합의 문제를 유의해야 합니다. 우리는 Grid Search 방법으로 k-fold 교차검증을 통해 최적의 C와 gamma를 구할 것입니다. GridSearhCV()를 보면, estimator로 SVM의 classifier인 SVC()가 사용되었으며 튜닝할 파라미터들(kernel, gamma, C)을 딕셔너리 형태로 만들어 GridSearchCV()에 넣습니다. 이때 k-fold 교차검증의 값을 10(cv=10)으로 설정합니다. GridSearchCV()는 사이킷런에 구현되어 있는 최적의 파라미터를 구하는 함수로, 함수 인자들에 대한 자세한 설명은 다음의 공식 문서에서 확인할 수 있습니다. 생성된 객체 clf에서 fit() 메소드를 실행하면, 교차 검증 성능이 가장 좋은 최적의 parameter를 찾아주고 활용하여 train 데이터에 대한 새로운 모델을 자동으로 생성합니다. 시각화에 편하고자 이번엔 3점 슛과 블로킹, 두 특징만 사용하여 최적의 parameter와 교차 검증 점수를 확인해보니, C : 1, gamma : 0.1, accuracy : 0.875라는 결과를 얻었습니다.

최적의 C와 gamma를 구했으니, decision boundary를 만들 수 있습니다. 이전에, 최적의 C와 gamma의 1/100과 100배에 해당하는 값들에 대해서도 모두 확인해보기 위해 값들을 C_candidates와 gamma_candidates에 저장한 모든 조합에 대해 학습된 모델을 classifiers에 저장하여 시각화해보겠습니다. 시각화를 위해 편의성을 생각하여 센터(C)를 1, 슈팅가드(SG)를 2로 표현하였으며 matplotlib로 시각화한 차트는 아래와 같습니다.


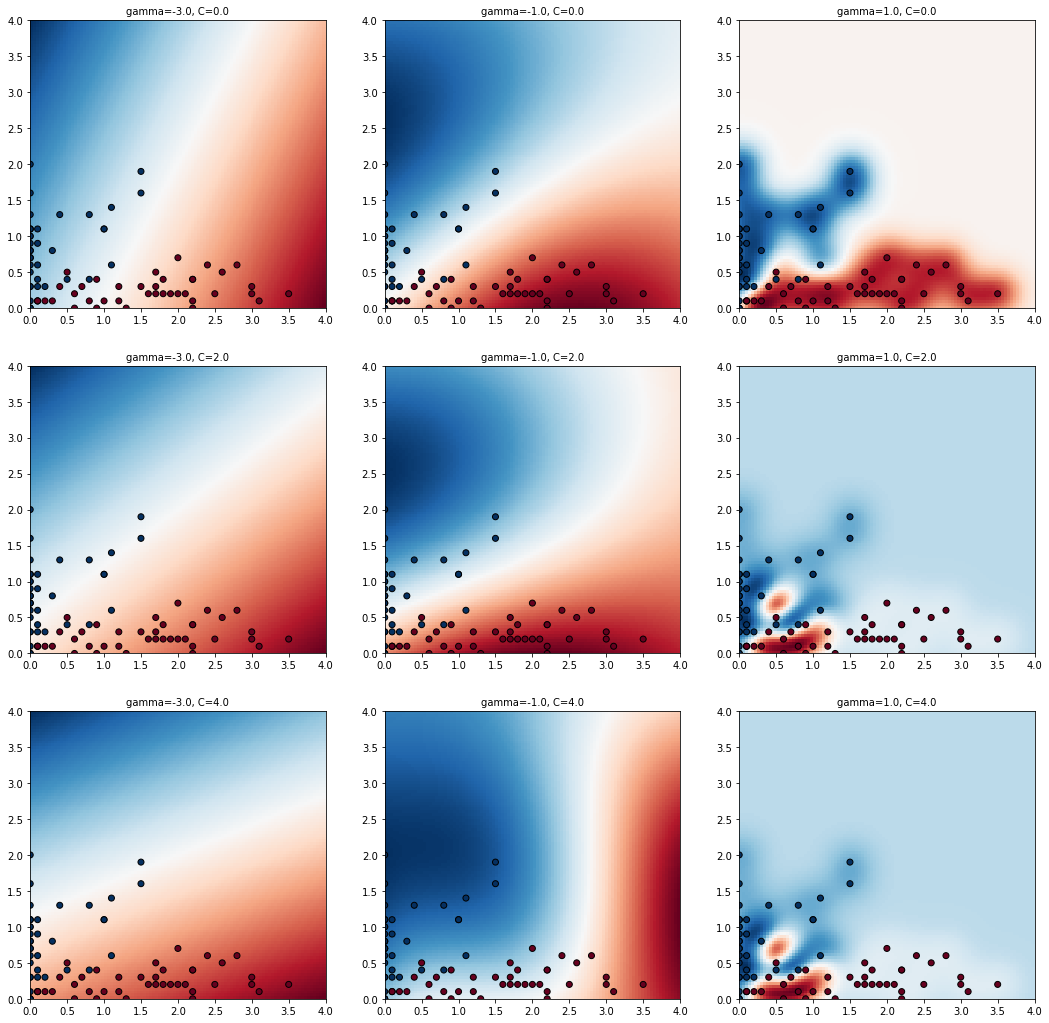
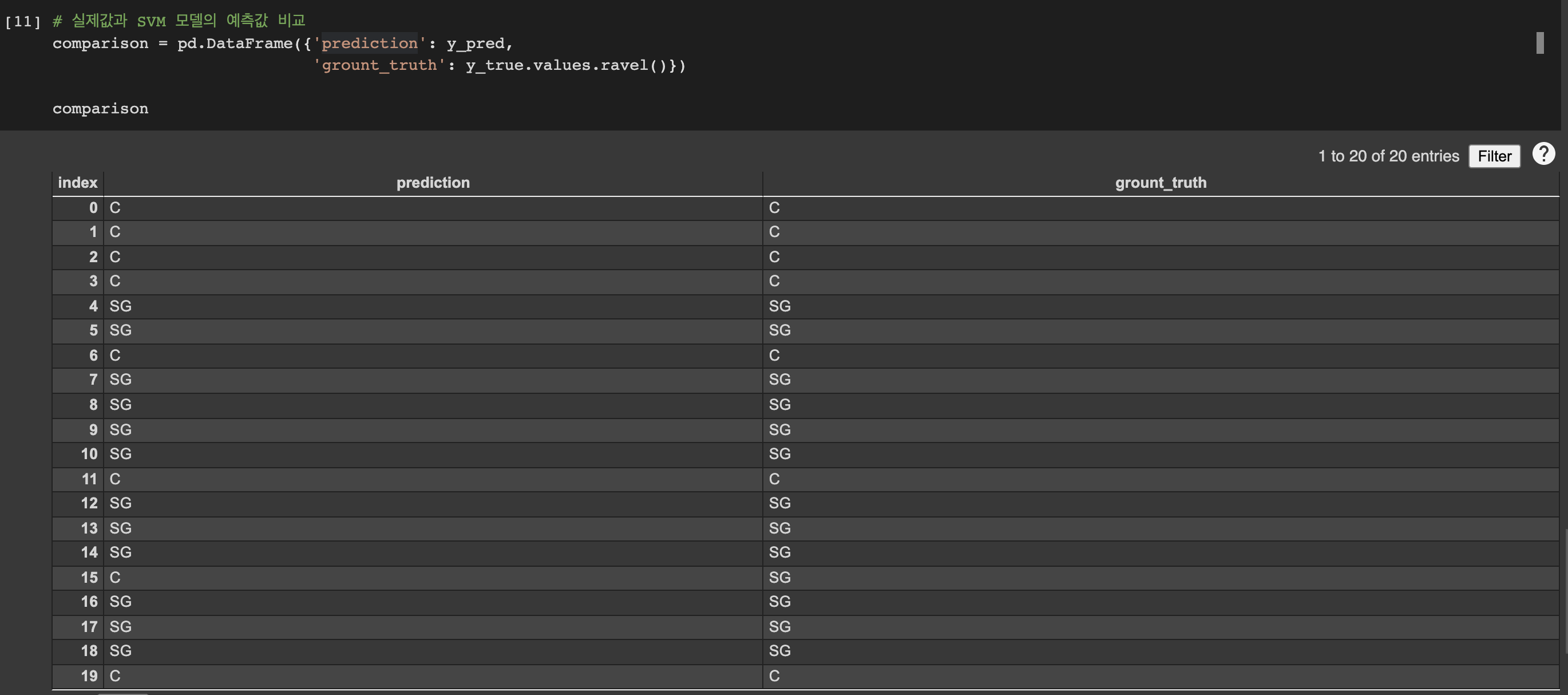
위의 9개의 차트 중, 가장 가운데에 있는 차트가 바로 GridSearchCV()를 통해 얻은 최적의 C와 gamma로 학습된 모델입니다. 파란색 부분과 빨간색 부분 사이의 흰색 부분에 있는 decision boundary를 기준으로 보면, 두 데이터의 군집이 균등하게 분류되어 있는 것을 확인할 수 있습니다. 이제 최적의 parameter만으로 생성한 모델 clf를 사용하여 테스트해보겠습니다. 사이킷런의 classification_report와 accuracy_score를 활용하면 모델의 accuracy 뿐만 아니라 정밀도(precision), 재현율(recall), f1-score까지 모두 확인할 수 있습니다. 정밀도, 재현율, f1-score 등의 모델 성능 평가는 다음 포스트에서 다루며 그때 다시 지금의 표를 분석해보겠습니다. accuracy는 0.95로 매우 높은 수치이며, 실제 데이터 프레임을 생성하여 실제값과 SVM 모델의 예측값을 비교하면 한 선수를 제외하고선 모두 정확한 예측을 했음을 알 수 있습니다. 물론 이 수치는 런타임을 다시 실행시마다 테스트 데이터와 훈련 데이터가 랜덤 하게 분류되므로 다를 수 있으니, 코드 실행 시 결괏값이 조금은 다를 수도 있습니다. 하지만 주목할 점은 최적의 parameter를 찾는 과정에서 모델 생성 과정까지 어렵지 않았음에도, 매우 높은 정확도를 보이는 점에서 SVM은 이전 포스트에서 첫 줄에 설명했듯이 "SVM은 kNN, Decision Tree와 마찬가지로 주로 classification을 위해 사용되는 알고리즘으로, 이해하기 어렵지 않은 알고리즘에 비해 성능이 매우 우수하여 지도학습 머신러닝 알고리즘으로 자주 사용됩니다."는 말이 실습을 통해 확실히 이해될 것입니다.

'AI > ML' 카테고리의 다른 글
| Decision Tree 실습 - 지니 계수 및 서울 지역 다중 분류 (1) (0) | 2022.01.19 |
|---|---|
| 머신러닝 모델의 성능을 알아보자 (0) | 2022.01.08 |
| SVM(Support Vector Machine) (0) | 2022.01.07 |
| kNN(k-Nearest Neighbors) 알고리즘 - 농구선수 포지션 예측(2) (0) | 2022.01.03 |
| kNN(k-Nearest Neighbors) 알고리즘 - 농구선수 포지션 예측(1) (0) | 2022.01.02 |