2022. 1. 2. 07:30ㆍAI/ML
이 포스트는 허민석님의 유튜브 머신러닝 내용을 정리한 글입니다. 실습 코드는 도서 나의 첫 머신러닝/딥러닝에서 발췌해왔습니다. 실습 코드와 자료는 링크의 Github에서 볼 수 있습니다.
이번에는 2020-21 시즌 NBA 농구 선수들의 데이터를 사용하여 특정 농구 선수의 포지션을 kNN 알고리즘으로 예측해보겠습니다. 데이터는 NBA 농구 선수들의 데이터에서 추출하였으며 우리는 특정 선수의 포지션을 예측하고 레이블과 비교하여 정확도를 측정해보겠습니다. 원래 실습은 2017 NBA 농구선수의 데이터를 사용하지만 이번 포스트는 2022년에 작성되었기 때문에 2020-21 시즌의 데이터로 실습하며, 파이썬을 활용한 데이터 크롤링부터 데이터 가공, 시각화의 과정을 모두 담고자 했습니다.
위 링크의 사이트에 접속하면, 다음의 표를 볼 수 있습니다.

우리의 일차적인 목표는 웹 페이지의 정보들을 가져와 판다스의 데이터 프레임의 형태로 가공한 다음, csv 파일로 생성하는 것입니다.
웹 페이지의 정보들을 가져오는 작업이 바로 크롤링으로, 인공지능뿐만 아니라 데이터와 관련된 모든 분야에서 크롤링은 매우 중요한 작업입니다. 파이썬에서는 이미 크롤링을 위한 다양한 라이브러리들이 준비되어 있는데, 이번엔 BeautifulSoup를 사용하여 크롤링을 하겠습니다. 참고로 파이썬의 크롤링 라이브러리는 대표적으로 BeautifulSoup, Selenium, Scrapy 등이 있으며 각각의 장단점이 있습니다. 예를 들어 지금처럼 정적인 페이지에서 단순히 데이터만 크롤링하기에는 빠르고 단순한 BeautifulSoup가 효과적이지만, 동적인 페이지 혹은 웹 페이지를 실제로 띄운 다음 페이지를 제어하는 것은 Selenium으로 할 수 있습니다. 따라서 보통 크롤링 시에는 BeautifulSoup와 Selenium을 적절한 상황에 조합하여 사용하는 경우가 많지만 이번에는 단순히 정적인 페이지에서의 텍스트 데이터만 가져오는 작업이기 때문에, BeautifulSoup만을 사용하여 크롤링했습니다. 다음의 실습 코드와 csv 파일은 링크의 깃허브에서 받아볼 수 있습니다.
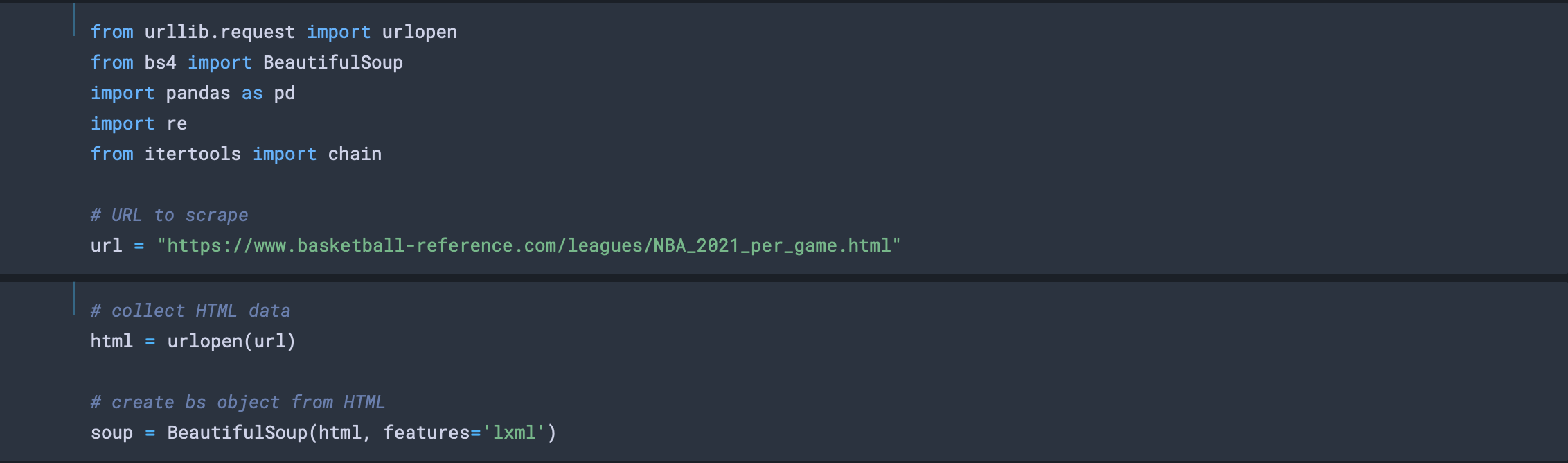
필요한 라이브러리를 임포트한 다음, 웹 페이지의 url을 변수에 넣어 저장해놓습니다. BeautifulSoup 등의 외부 라이브러리는 따로 설치가 필요합니다. 이제 웹 페이지 링크에서 BeautifulSoup의 object를 생성하는데, lxml은 파이썬에서 사용되는 내부적으로 트리 구조를 가지는 마크업 언어인 XML을 해석하는 프로그램(parser)입니다. 다음의 그림을 보면 이해가 쉬울 것입니다. mac os 기준 웹 페이지에서 option + command + u를 누르면 다음의 창을 볼 수 있을 것입니다.

웹 페이지의 HTML 소스를 볼 수 있습니다. 이제 왼쪽 위의 나침반 모양의 버튼을 클릭한 다음 표 전체 부분이 파란색 박스로 되는 위치에 놓고 클릭하면, 표의 소스를 볼 수 있습니다.
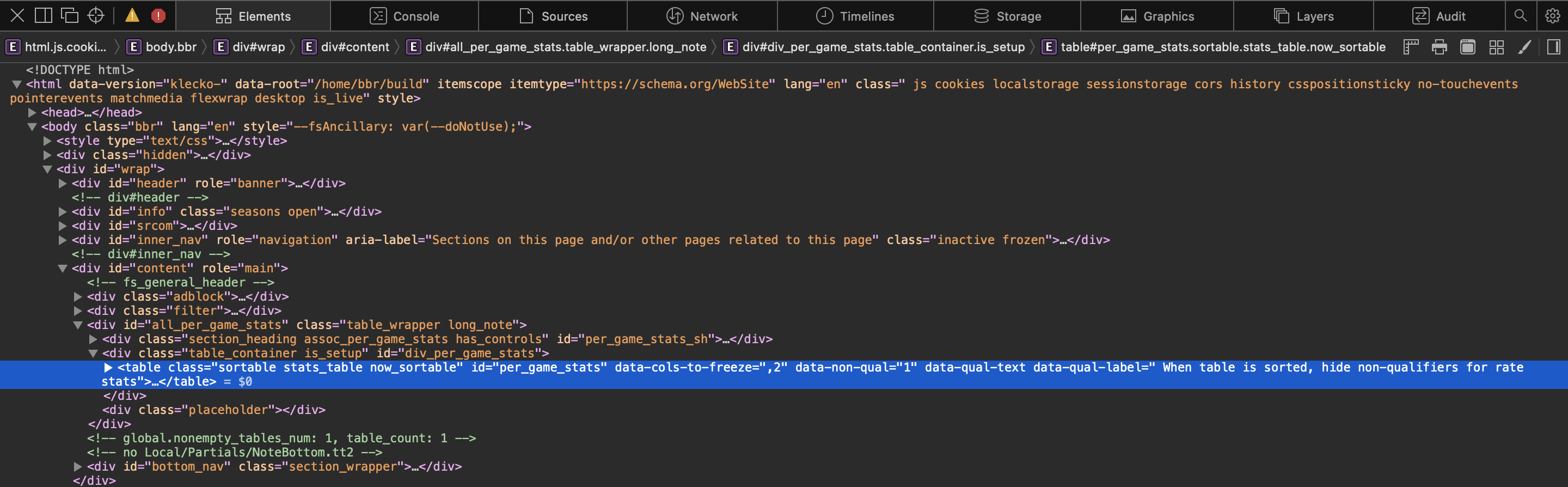
아래의 사진처럼 펼쳐보며 아래 소스 위에 마우스를 올리며 웹 페이지를 보면 노란색 박스 부분으로 색칠되어 우리는 어느 소스가 표의 어느 부분에 해당하는지 알 수 있습니다. 물론 HTML에 대한 기초적 지식이 있다면 좋지만, 소스를 자세히 보면 보라색 글씨의 <thead>, <tr>, <th></th>를 볼 수 있습니다. 모두 table 태그로, HTML에서 표를 구성하는 요소들입니다. <thead>로 시작했다면 </thead>로 닫아줘야 하며, 마찬가지로 <tr>로 시작했다면 </tr>로 닫아줘야 합니다. 이러한 구성이 위에서 말한 트리 구조를 가진의 XML 형식입니다. 먼저 BeautifulSoup의 find_all 함수를 사용하여 표의 제목인 Rk, Player, Pos, Age 등의 정보를 쉽게 추출할 수 있습니다.

아래 코드를 보면 th, tr의 table 태그를 볼 수 있습니다. 우리는 이번 크롤링에서 HTML에 대한 자세한 지식까지 필요로 하지는 않지만, 기초 지식이 다소 필요하다는 부분이 이러한 면입니다. 코드를 그대로 해석해보면 "행을 만드는 table row 태그 중 첫 번째(표의 제목 부분이 저장되어 있습니다.)에서 table head 태그를 찾아, 해당 태그의 텍스트를 리스트로 만든다"로 해석할 수 있습니다. 바로 위의 사진을 보며 이해하면, <tr> 하위의 <th>에서 형광색 부분의 Rk, Player, Pos 등의 텍스트를 추출하며, 이렇게 만든 headers 리스트를 출력해보면 정상적으로 데이터를 추출했음을 알 수 있습니다. 이제 우리는 크롤링하여 추출한 데이터를 보며 Player(선수 이름), Pos(포지션), 3P(3점 슛), 2P(2점 슛), TRB(리바운드), AST(어시스트), STL(스틸), BLK(블로킹)의 데이터만을 사용할 것을 판단할 수 있습니다.

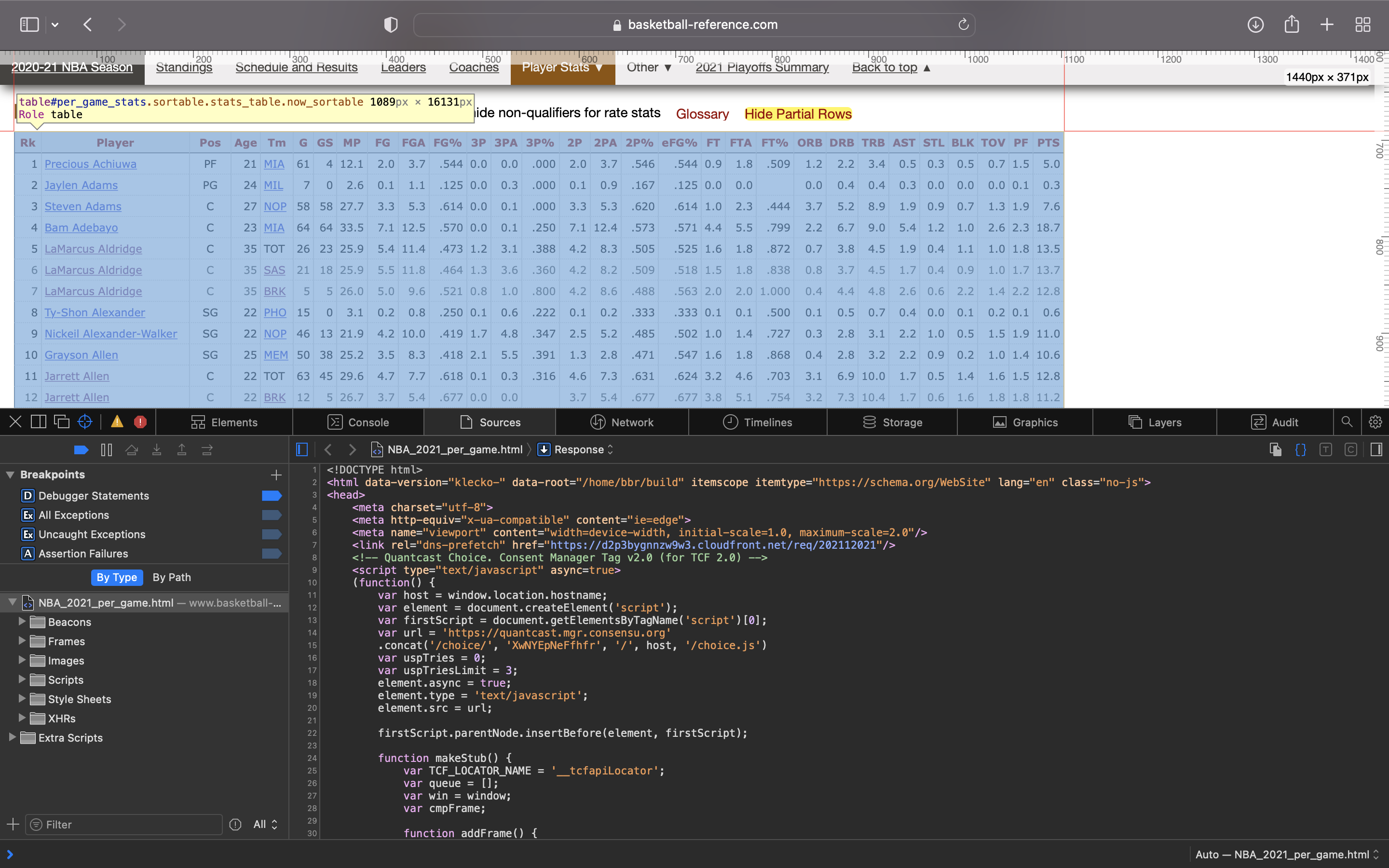
이제 각 행의 데이터를 추출해보겠습니다. 이번에는 <thead> 아래의 <tbody>를 살펴보면, <tr class="full_table data-row="0">을 볼 수 있습니다. 사실 해당 웹 페이지를 처음 열면 아래 사진에서처럼 Rk 5, 6, 7등이 한 선수임에도 불구하고 팀을 옮기며 기록이 따로 적혀 있습니다. 노란색으로 그어진 Hide Partial Rows를 클릭하면 되지만, 우리는 이러한 버튼 클릭 여부 하나만을 위해 Selenium을 사용하고 싶지는 않습니다. 그렇다면 페이지 소스를 조금 자세히 들여다보겠습니다.



소스를 자세히 들여다보면, class=""부분에서 차이가 있는 것을 알 수 있습니다. 마우스를 갖다 대며 확인해보면 "full_table"은 Hide Partial Rows를 눌렀을 시 나타나는 행의 클래스만을 표현하며, "italic_text partial table"은 한 선수의 중복된 기록까지 담은 클래스임을 눈치챌 수 있습니다. 그렇다면 우리의 목표는 100명의 서로 다른 선수들의 데이터를 추출하는 것임으로 full_table이라는 class name 속성을 이용하면, 원하는 데이터만 추출할 수 있습니다. 또한 마찬가지로, 위에서 Player, Pos, 3P, 2P, TRB 등의 속성들만 추출하고자 했는데 이 또한 아래 그림처럼 data-stat이라는 속성을 지정해주면, 우리는 "웹 페이지의 표에서 원하는 데이터만 따로 추출하여 파이썬의 리스트로 저장"하는 작업을 완료할 수 있습니다. 코드와 그림을 동시에 보며 이해하면 보다 쉬울 것입니다.


이제 리스트에 저장된 데이터들을 pandas의 데이터 프레임 형식으로 만든 다음 csv 파일로 저장하겠습니다. 그보다 먼저 이번 실습에서는 kNN 알고리즘의 효율성을 보여주고자 농구 모든 포지션이 아닌 서로의 역할이 꽤 차이나는 센터(C)와 슈팅가드(SG) 포지션 각각 50명씩, 총 100명의 데이터에 대해서만 레이블을 갖도록 하겠습니다. 이를 위해 판다스의 데이터 프레임으로 만든 다음, Pos열의 C와 SG만 따로 뽑아내어 상위 50명의 데이터 프레임을 생성한 다음, 두 데이터 프레임을 다시 합치는 형식의 작업을 거칠 것입니다. 이는 특히 어렵지는 않기 때문에 코드와 결과를 보며 간략히 말하겠습니다.
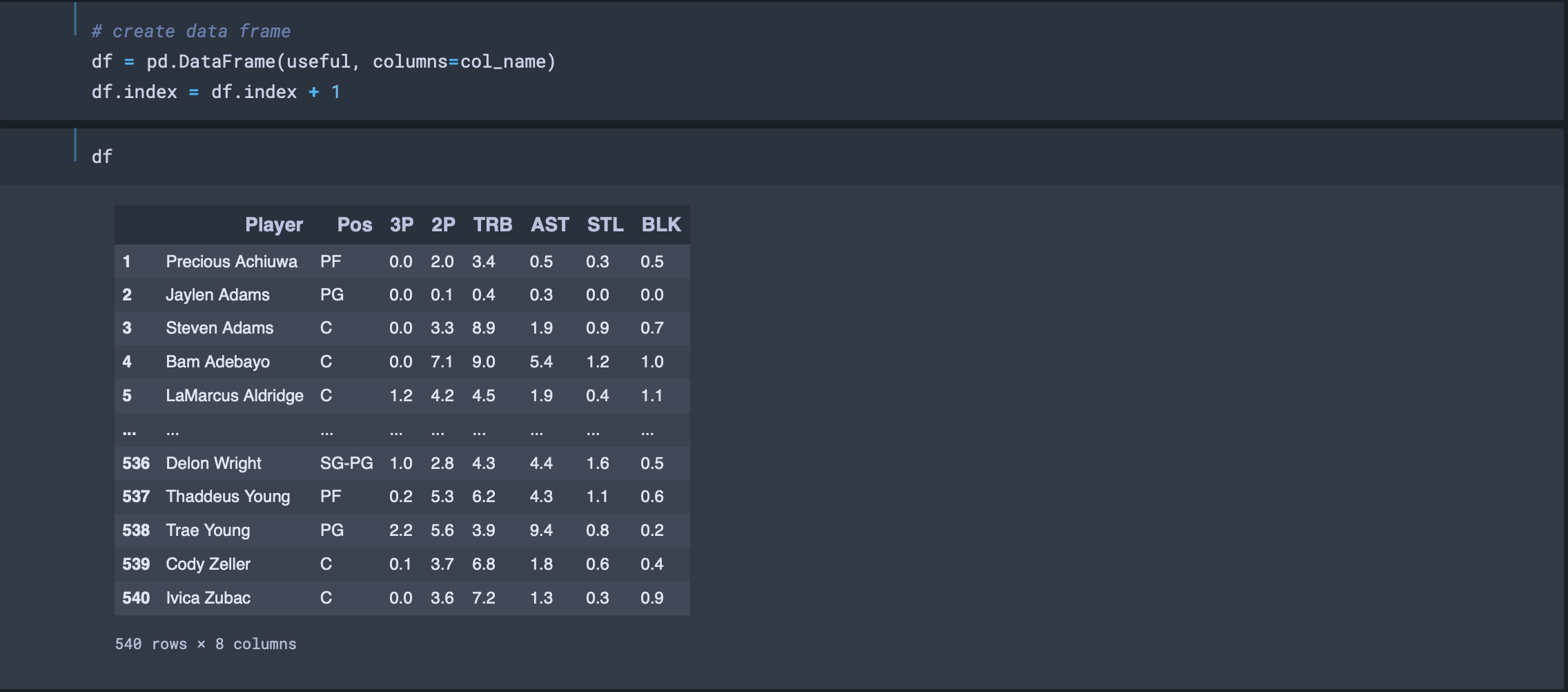




미리 생성해둔 col_name을 제목으로 df를 만들었으며 df['Pos'] == 'C', df['Pos'] == 'SG'로 두 포지션에 해당하는 선수들의 데이터만 50명씩 따로 뽑았으며, 두 데이터 프레임을 하나의 useful_df 데이터 프레임으로 합친 다음 csv 파일로 저장했습니다. 이제 다음 포스트에서는 크롤링으로 만든 csv 파일을 활용하여 농구 선수 포지션 예측하는 모델을 만드는 작업을 하겠습니다.
'AI > ML' 카테고리의 다른 글
| SVM(Support Vector Machine) 실습 - 농구 선수 포지션 예측 (0) | 2022.01.08 |
|---|---|
| SVM(Support Vector Machine) (0) | 2022.01.07 |
| kNN(k-Nearest Neighbors) 알고리즘 - 농구선수 포지션 예측(2) (0) | 2022.01.03 |
| Decision Tree + ID3 알고리즘 (0) | 2021.12.24 |
| kNN(k-Nearest Neighbors) 알고리즘 (0) | 2021.12.23 |