2020. 6. 23. 02:30ㆍAI/TF2.0 Keras
포스트의 코드와 설명은 "시작하세요! 텐서플로 2.0 프로그래밍"을 참고하여 작성했습니다.
이번 포스트에서는 XOR문제를 TensorFlow2.X버전의 Keras API를 이용해 풀어보겠습니다. XOR문제는 이미 "모두를 위한 딥러닝" 포스트에서 다룬 적이 있지만, Keras에 대해 가장 쉽게 다가갈 수 있는 문제이기 때문에 이번 포스트에서는 Keras 활용에 중점을 두어 설명하겠습니다.
· 인공지능의 첫 번째 겨울, XOR 문제
먼저 XOR(배타적 논리합)은 입력이 2개임을 가정할 때 입력 간의 비동일성을 판단하는 것으로, 쉽게 말해 두 입력이 다를 때만 XOR연산이 참이 되는 네트워크를 말합니다. 아래의 진리표를 보면 XOR 네트워크를 쉽게 이해할 수 있을 것입니다.
| X1 | X2 | XOR(X1,X2) |
| 1 | 1 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
하나의 퍼셉트론만으로 풀 수 있는 AND/OR 네트워크와는 달리 다층 퍼셉트론(MLP)을 이용해야 하는 XOR문제의 경우, TF2.X 버전에서 Keras를 이용해 쉽게 풀 수 있습니다. 일전에 말했듯이 이미 "모두를 위한 딥러닝"에서 XOR문제를 풀어본 적이 있으므로 Keras를 이용하지 않은 코드와 자세한 풀이과정은 링크에서 확인하시길 바랍니다. 아래는 코드 전문입니다.
"""
@IDE: Pycharm
@Environment: TF 2.1.0, python 3.7.7
@citation: 시작하세요! 텐서플로 2.0 프로그래밍
@author: Hwanhee kim
@Rewrite: childult-programmer
@Github: https://github.com/childult-programmer
"""
import tensorflow as tf
import numpy as np
# XOR data
x = np.array([[1, 1], [1, 0], [0, 1], [0, 0]])
y = np.array([[0], [1], [1], [0]])
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=2, activation='sigmoid', input_shape=(2,)),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.1), loss='mse')
history = model.fit(x, y, epochs=3000, batch_size=1)
model.summary()
print(model.predict(x))
Keras를 중점으로 코드를 살펴보겠습니다. 먼저 model에 대해 알아보겠습니다.
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=2, activation='sigmoid', input_shape=(2,)),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])model은 keras에서 딥러닝 연산을 편하게 만들어주는 추상적인 클래스입니다. model은 여러 함수와 변수의 묶음을 가지는 딥러닝의 가장 기본적이고 핵심적인 단위로 앞으로 많이 보게 될 것입니다. 이 model에서 가장 많이 쓰이는 구조가 tf.keras.Sequential입니다. Sequential은 "일련의", "순차적인"이라는 뜻으로, 말 그대로 레이어를 일직선으로 배치한 것입니다. 이때 레이어는 뉴런들이 합쳐진 단위로, 뉴런은 다른 말로 퍼셉트론(perceptron), 유닛(unit)으로도 불립니다. 아래는 Sequential 구조를 그림으로 표현하였습니다.
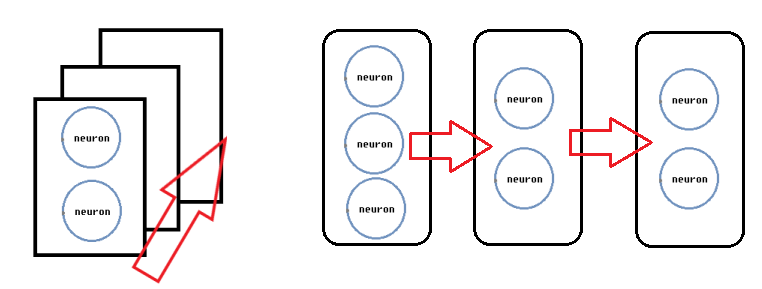
이제 레이어를 정의할 차례입니다. Dense는 가장 기본적인 레이어로, 레이어의 입력과 출력 사이 모든 뉴런을 서로 연결하는 완전 연결(fully connected, 전결합) 레이어입니다. Dense의 units은 레이어를 구성하는 뉴런의 수를 의미합니다. 뉴런의 수가 많을수록 레이어와 전체 모델의 성능은 좋아지지만, 계산량이 많아지고 메모리를 많이 차지해 속도가 늦어진다는 단점도 있습니다. activation은 말 그대로 activation function, 활성화 함수입니다. 활성화 함수로는 sigmoid, ReLU 등 다양한 함수들이 있지만, 여기서는 sigmoid를 사용하고 있습니다. input_shape은 첫 번째 레이어에서만 정의하는 인자로, 입력의 차원 수를 알려줍니다. 여기서는 데이터가 2개의 입력을 받는 1차원 numpy array(예: [1, 1], [1, 0] 등)이기 때문에 (2,)로 정의했습니다. 위의 model의 구조를 그림으로 나타내면 아래와 같습니다. 그림에서는 input과 output 사이의 모든 뉴런이 서로 연결되어 있으며 이때 실선은 weight을 나타냅니다. 입력에서 첫 번째 Dense레이어로 향하는 실선은 4개, 첫 번째 Dense레이어에서 두 번째 Dense레이어로 향하는 실선은 2개임을 확인할 수 있습니다. 다만 뒤에 model.summary()를 설명할 때 다시 언급하겠지만 아래의 구조는 weight을 중점으로 설명하기 위해 bias를 빼고 작성한 구조입니다.

다음은 model을 준비하고 학습하는 과정입니다.
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.1), loss='mse')
history = model.fit(x, y, epochs=3000, batch_size=1)먼저 model.compile을 보겠습니다. model.complie에서 model의 최적화 함수(optimizer), 손실 함수(loss), 기준 리스트(metrics)를 정의합니다. optimizer은 딥러닝의 학습식을 정의하는 인자로 코드에서는 keras.optimizers에 미리 정의된 SGD(확률적 경사 하강법)를 사용하며 동시에 learning_rate을 0.1로 초기화하고 있습니다. 다양한 최적화 함수들에 대해서는 다음번에 자세히 알아보도록 하겠습니다.

loss는 손실 함수를 정의하며 코드에서는 'mse'(Mean Squared Error, 평균 제곱 오차)를 사용합니다. mse에 관해서는 "모두를 위한 딥러닝" 02.Simple Linear Regression에서 알아본 적이 있으므로, 링크의 포스트를 참고하시면 좋습니다. 마지막으로 이번 코드에서는 사용하지 않았지만 모델의 성능을 평가하고자 할 때는 metircs=['binary_accuracy"'와 같이 metrics를 설정합니다. model.compile의 optimizer와 loss를 보면 optimizer는 keras에 미리 정의된 최적화 함수(SGD)를 불러오는 반면 loss는 keras의 함수를 이용하지 않고 문자열 식별자로 손실 함수를 나타냅니다('mse'). 이처럼 model.compile에는 keras에 정의된 함수를 사용하든 문자열 식별자로 직접 함수를 지정하든 상관이 없습니다.
이제 model.fit을 보겠습니다. model.fit은 모델을 실제로 학습하는 단계로 입력 데이터(x)와 레이블, 기대 출력(y)을 넣고 epoch(전체 데이터셋에 대한 학습 반복 횟수)와 batch_size(훈련 데이터의 수)를 정합니다. 코드에서는 총 3000번 학습하며 한 번의 epoch에 하나의 데이터를 학습합니다. batch_size에 대해 더욱 자세히 설명하면 batch_size가 작을수록 weight의 갱신이 자주 일어난다는 의미로 코드에서 batch_size=1은 한 번의 학습마다 한 번씩 데이터와 레이블을 맞춰보며 weight을 갱신합니다. 반면 batch_size를 큰 수로 설정하면 그 수만큼 학습한 뒤 weight을 갱신하는 것으로, 학습의 횟수에 비해 weight의 변화가 다소 둔할 수 있습니다.
마지막으로 model의 구조를 출력하고 학습한 뒤 model을 평가하는 코드입니다. 실제로 모델을 학습한 뒤의 출력 화면을 같이 보며 알아보겠습니다.
model.summary()
print(model.predict(x))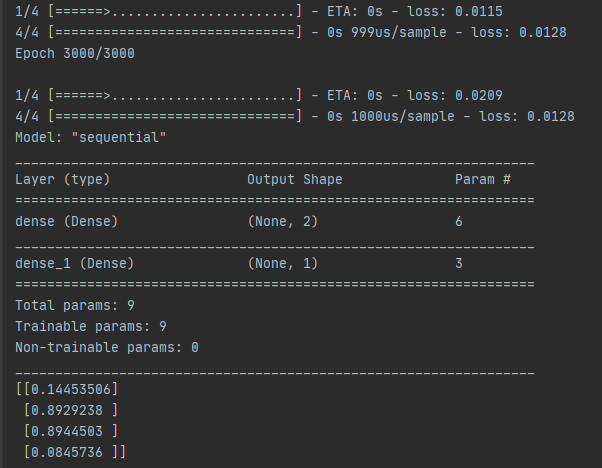
model.predict 먼저 보면 model.predict()에 입력을 넣으면 학습을 완료한 뒤의 네트워크 출력 결과를 알 수 있습니다. print()를 이용하여 출력 결과를 보면 첫 번째와 네 번째 값을 0에, 두 번째와 세 번째 값은 1에 가까운 것을 확인할 수 있습니다. 다른 말로, 학습이 아주 잘 되었다는 뜻입니다. 실제로 Model: "sequential"위의 학습 결과를 보면 loss: 0.0128로, 아주 작은 값을 가지는 것을 확인할 수 있습니다. model.summary는 model 네트워크의 구조를 출력해줍니다. Dense레이어를 다중으로 가지고 있는 MLP구조로, 출력 화면에서 하나 눈에 띄는 점은 Param #에서 첫 번째 레이어에는 6개, 두 번째 레이어에는 3개의 parameter가 있다고 나옵니다. 위에서 model의 구조를 보면 첫 번째 레이어에는 4개, 두 번째 레이어에는 2개임을 확인하였는데 이와 같은 결과가 나오는 이유는 무엇일까요? 일전에 model의 구조 그림을 설명할 때 말했듯이 레이어는 원래 기본적으로 bias를 포함하고 있습니다. bias를 포함한 model의 구조를 다시 표현하면 아래와 같습니다. model.summary의 출력과 같이 입력에서 첫 번째 Dense레이어로 향하는 실선은 6개, 첫 번째 Dense레이어에서 두 번째 Dense레이어로 향하는 실선은 3개임을 확인할 수 있습니다.

이제 코드에 대한 분석이 모두 끝이 났습니다. 작성하지는 않았지만 weight과 bias는 model.weights에 저장되어 있기 때문에, 원한다면 간단한 코드 작성으로 확인하실 수 있습니다. model.weights을 이용해 weight을 확인하는 코드는 아래에 작성해놓겠습니다. model.weights에 대한 자세한 것은 다음번에 다루도록 하겠습니다.
for weight in model.weights:
print(weight)우리는 model을 정의하고 학습하는 단 몇 줄의 코드만으로 3000번을 학습하고 loss: 0.0128이라는 아주 좋은 학습 결과를 얻을 수 있었습니다. 이것이 Keras의 엄청난 장점입니다. 우리는 Keras를 이용하지 않고 작성했을 때 아래의 코드처럼 많은 줄을 작성해야만 헀습니다. 하지만 이러한 Keras에서는 model을 만들고(model = tf.keras.Sequential) 학습을 준비하는 것(model.compile, model.fit)만으로도 학습 결과를 볼 수 있고 모델의 구조나 네트워크 출력 결과, weight 등 필요에 따라 원하는 값을 확인할 수 있습니다(앞에서부터 model.summary, model.predicdt, model.weights). 이처럼 Keras는 TF2.X 버전을 이용하여 딥러닝을 하신다면 꼭 알아두어야 하는 라이브러리라고 생각합니다.

