2020. 4. 17. 02:00ㆍAI/모두를 위한 딥러닝
이 포스트는 모두를 위한 딥러닝 - Tensor Flow를 정리한 내용을 담았습니다.
누구나 이해할 수 있는 수준으로 설명하고자 하였으며 LAB의 코드는 TF2.0에 맞추어 재작성되었습니다.
이번 포스트에서 우리는 05 Logistic Regression(1)과 05-1 Logistic Regression(2)에서 배운 내용들을 텐서플로우에서 구현해보며 복습해보겠습니다.
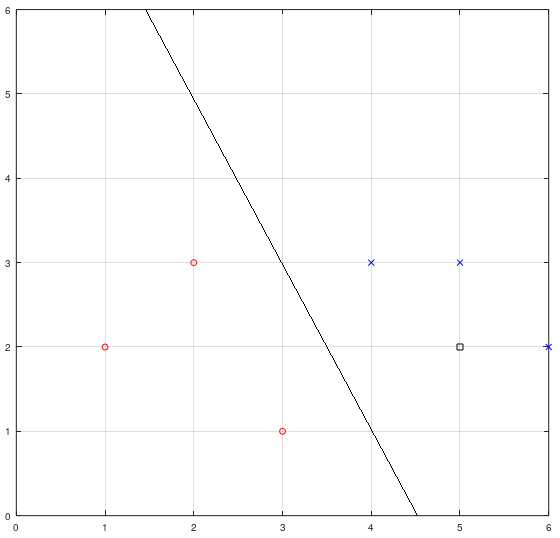
먼저 아래의 그래프 1.1을 보겠습니다. 그래프 1.1은 코드 1.1의 Training data set (x_train)의 좌표를 점으로 표현한 그래프입니다. y_train의 0에 대칭되는 x_train의 [1, 2], [2, 3], [3, 1]은 ●으로, y_train의 1에 대칭되는 x_train의 [4, 3], [5, 3], [6, 2]는 ×로, 그리고 Test data set인 x_test는 □로 좌표점을 찍어 표현하였습니다.
●와 × 사이의 직선은 Logistic regression의 적절한 Hypothesis의 한 예시입니다.
이제 텐서플로우 코드를 통해 Logistic regression의 Hypothesis, Cost function, Gradient descent를 정의하고 Epochs에 따른 cost의 변화를 살펴보겠습니다. 먼저 전체 코드를 본 후, 함수 및 line별로 자세히 살펴보겠습니다. 아래는 코드 전문입니다.


먼저 line 7 - 28을 보겠습니다. line 3 - 4에서 텐서플로우와 넘파이를 선언하고, 뒤이어 line 7 - 25 Training Data set(x_train, y_train), 그리고 Accuracy를 위한 Test data set을 numpy 배열로 선언합니다. line 27의 tf.data.Dataset.from_tensor_slices(...)에서는 텐서플로우에서 제공하는 API인 Dataset을 이용하여 데이터를 공급하고 있습니다. 그렇다면 이렇게 API를 이용하여 데이터를 처리하는 이유는 무엇일까요? 데이터를 어느 한 지점에서 특정 공간으로 데려오는 데에는 많은 장애물들이 있어 데이터 처리에 오류(중복 유실 등)가 일어날 수 있습니다. 이를 막고자 입력 파이프라인을 만들어 데이터를 효율적으로 흐르도록 만드는데, 이러한 작업을 실행하는 것이 바로 tf.data.Dataset.from_tensor_slices(...)입니다. 실제로는 from_tensor_slices 클래스 메서드를 사용하여 데이터셋(x_train, y_train)을 만들고 이 데이터셋을 batch()에 주어진 크기만큼 자동으로 처리하는 작업이 일어납니다.

line 30 - 35에서는 W, b를 임의의 값을 가진 배열로 선언하고 logistic_regression 함수에서 tf.math.sigmoid()를 통해 hypothesis를 정의했습니다. 이 과정에서 눈여겨 볼만한 것은 hypothesis를 구할 때 tf.div(1., 1. + tf.exp(...))와 같이 식을 늘어놓아도 실행에 문제는 없지만 sigmoid()를 활용하여 가독성을 높였다는 점입니다.
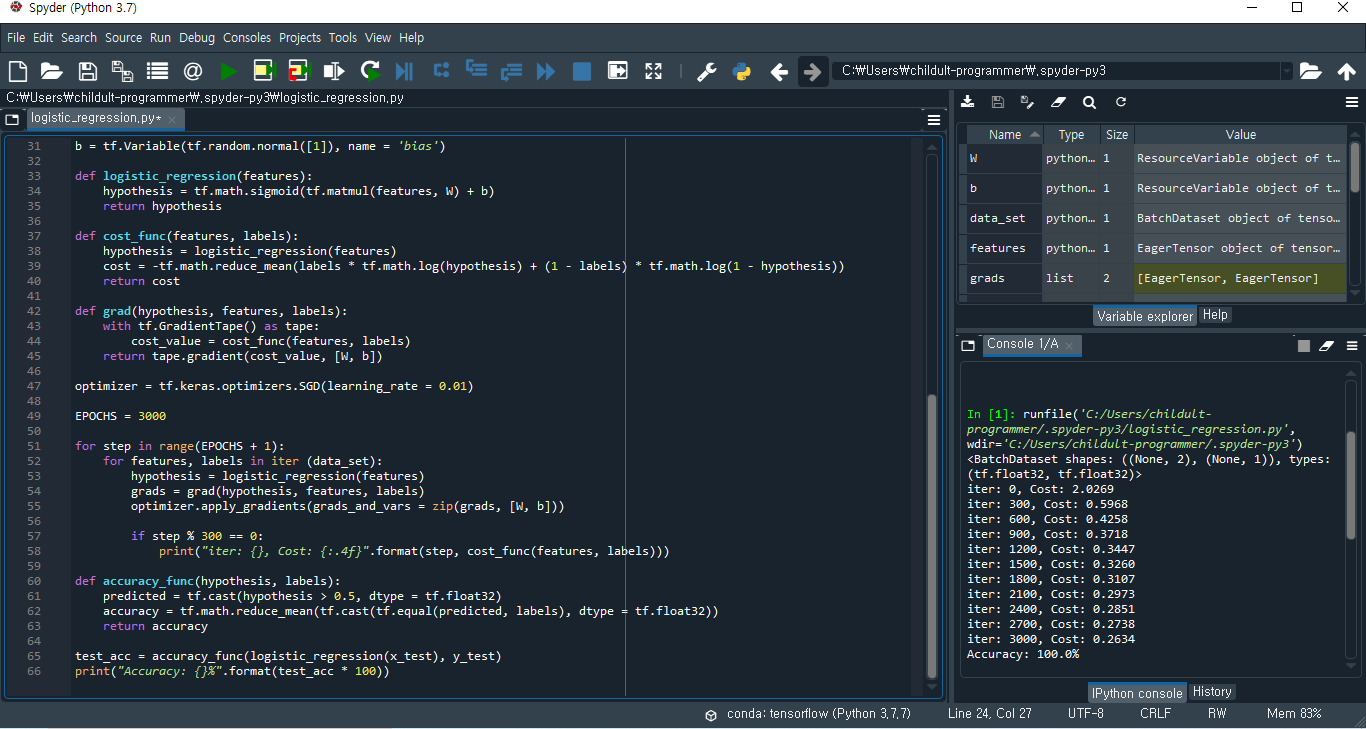

line 37 - 47을 보겠습니다. 먼저 line 37 - 40은 cost function을 구현한 코드입니다. 저번 포스트에서 "cost function을 한 줄로 표현함으로써 ... 텐서플로우 코드를 보다 보기 좋게 작성할 수 있습니다."라고 했는데, 이룰 보여주는 문장이 바로 line 39, cost = -tf.math.reduce_mean(...)입니다. 다음으로 line 42 - 45에서는 cost에 대해 (W, b)를 미분한 값을 리턴합니다. with구문이나 return tape.graident(...)때문에 다소 어려워 보일 수 있지만 예전 02-2 Simple Linear Regression LAB의 코드를 축약하여 함수로 작성하였을 뿐, 내용은 별반 다르지 않습니다. 마지막으로 아래의 line 47은 학습 속도를 0.01로 정하는 코드입니다. 사실 tf.keras.optimizerss와 SGD(확률적 경사 하강법)가 사용되어 현재까지 배운 수준을 뛰어넘는 어려운 코드입니다. 다만 지금은 영상에 나오는 tf.train.GradientDescentOpitmizer(...)를 사용하지 않은 이유가 TF v2.0에서 기본적으로 tf.train을 지원하지 않아 tf.keras.optimizers로 구현했다는 점만 알아두겠습니다. 자세한 내용은 stackoverflow와 tensorflow를 참조해주시길 바랍니다.

먼저 용어 하나를 알고 코드로 넘어가겠습니다. 전체 데이터셋에 대해 한번 학습을 완료한 상태를 one Epoch라고 부릅니다. 따라서 line 49의 EPOCHS는 전체 데이터셋에 대해 앞으로 학습을 반복할 횟수를 말합니다. line 51 - 55는 (EPOCHS + 1) 번만큼 반복하며 data_set을 토대로 hypothesis와 grads를 구해 W와 b를 업데이트해줍니다. optimizer.apply_gradient()는 gradient와 해당 변수 리스트를 인수로 받아 W, b를 최적 값으로 업데이트해주는 역할을 합니다. line 57 - 58에서는 300번 반복할 때 마다 반복횟수와 cost를 출력하도록 작성되어있습니다.

코드의 마지막을 보겠습니다. accuracy_func함수는 예상값과 실제값이 얼마나 비슷한지를 반환하는 함수입니다. predicted = tf.cast(hypothesis > 0.5, ...)은 hypothesis가 0.5보다 크다면 True(1), 크지 않다면 False(0)을 반환합니다. tf.cast()에 대한 사용법은 tensorflow 공식 홈을 확인해주시길 바랍니다. line 65 - 66은 처음에 정의한 x_test, y_test를 accuracy_func()에 넣어 반환된 값을 출력하여 예상값과 실제값의 차이를 정확도(%)로 나타냅니다.
이로써 코드를 차근차근 보며 텐서플로우에서 Logistic regression을 구현해보았습니다. 사실 이전에 배운 simple Linear regression이나 multi-variable Linear regression을 구현한 코드와 크게 다르지 않아 많이 어렵지는 않으셨을것이라 기대합니다. 다만 tf.data.Dataset이나 tf.keras.optimizers, optimizers.apply_gradient()처럼 처음보는 문법에 당황하셨을 수도 있지만, stackoverflow.com 이나 tensorflow python symbols를 참고하시면 좋을 것 같습니다.
이번 포스트는 강의의 코드와 다르게 작성되었습니다. tensorflow 2.0으로 업그레이드되며 eager mode가 기본으로 활성화되어있다는 점과 tf.train.GradientDescentOptimizers를 지원하지 않는다는 점 등의 오류가 있는 부분을 재작성하였습니다. 다음 포스트에서는 Softmax regression에 대해 알아보겠습니다.
'AI > 모두를 위한 딥러닝' 카테고리의 다른 글
| 06-1. Softmax classification (0) | 2020.04.19 |
|---|---|
| 06. Softmax classification - Multinomial classification (0) | 2020.04.18 |
| 05-1. Logistic Regression(2) (0) | 2020.04.13 |
| 05. Logistic Regression(1) (0) | 2020.04.10 |
| 04-1. Multi-variable Linear Regression LAB (2) | 2020.04.07 |