2020. 4. 10. 02:05ㆍAI/모두를 위한 딥러닝
이 포스트는 모두를 위한 딥러닝 - Tensor Flow를 정리한 내용을 담았습니다.
누구나 이해할 수 있는 수준으로 설명하고자 하였으며 LAB의 코드는 TF2.0에 맞추어 재작성되었습니다.
이번 포스트에서는 데이터 분류 기법 중 하나인 Logistic Regression(로지스틱 회귀)에 대해 알아보겠습니다. 먼저 Logistic Regression의 기본이 되는 Classification(분류)에 대해 알아보겠습니다.
·Classification (분류)
분류는 이진 분류(Binary classification)와 다중 분류(Multi-class classification)로 나뉩니다.
이진 분류(Binary classification)는 시험의 Pass/Fail, 스팸메일인지 스팸메일이 아닌지(Spam/Ham)와 같이 예/아니오로 구분될 수 있는 분류를 의미합니다. 우리는 앞으로 Pass, Ham와 같은 경우를 positive class, Fail, Spam과 같은 경우를 negative class로 나눠 코드에서 0과 1로 표현하겠습니다. 많이들 이진 분류의 예시를 보고 positive class(0)가 긍정적 예시, negative class(1)가 부정적 예시인 경우로 착각하지만, 긍정과 부정이 아니라 주로 학습(예측)하고자 하는 대상이 positive class로 정하는 것이 일반적입니다.
다중 분류(Multi-class classification)는 구글 번역기에서 입력한 텍스트가 영어인지, 한국어인지, 일본어인지 등, 분류할 클래스가 여러 가지인 경우입니다. 이진 분류가 클래스가 2개인 경우라면, 다중 분류는 클래스가 3개 이상인 경우이며 OvO나 OvR 등의 방법을 이용하여 여러 개의 이진 분류 문제로 변환하여 풀 수 있습니다. 다중 분류에 대해 자세한 내용은 이후에 다시 알아보겠습니다.
·Logistic Regression (로지스틱 회귀) VS Linear Regression (선형 회귀)
그렇다면 Logistic Regression이 이전에 배운 Linear Regression과 어떻게 다른지 알아보겠습니다.
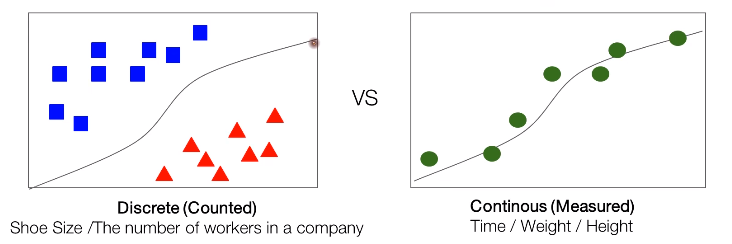
왼쪽은 Logistic Regression을, 오른쪽은 Linear Regression을 나타낸 그래프입니다.
Logistic Regression을 살펴보면 데이터들이 ■ 혹은 ▲, 두 부류로 나뉜 것을 볼 수 있습니다. 이처럼 Logistic은 분류될 수 있고, 셀 수 있는 특성을 가지고 있습니다. 데이터 사이의 선은 Hypothesis로, 데이터를 분류하는 기준이 됩니다. 240, 250, 260등으로 분류되는 신발 사이즈나 회사의 직원 수는 로지스틱 회귀의 좋은 예입니다.
반면 Linear Regression에서는 데이터들이 연속적이고, 측정할 수 있다는 특징을 가지고 있습니다. 데이터를 이은 선은 데이터를 가장 잘 대변하는 Linear Regression의 Hypothesis입니다. 시간, 몸무게, 키 등은 연속적인 값으로 표현하며 이들은 선형 회귀의 대표적인 예시입니다.

위는 score에 따른 Pass(1)와 Fail(0)을 나타낸 그래프입니다. 그래프에서 빨간색으로 표시된 x와 파란색으로 표시된 o는 Fail과 Pass를 나타냅니다. 이때 Fail과 Pass의 경계가 되는 score는 2-3 사이인 것으로 보입니다. 이 데이터들을 대변하는 Hypothesis는 기존의 H(x)로는 힘들어 보입니다. 실제로 데이터들이 연속적이지 않고 0 또는 1로 이분적이기 때문에 초록색으로 그은 Hypothesis는 데이터들을 잘 대변하는 것 같지는 않아 보입니다. 따라서 우리는 데이터들을 대변할 수 있는 새로운 함수가 필요합니다. 새로운 함수는 Sigmoid function이라 하고 g(H(x)) 혹은 g(z)로 표현됩니다. 아래 그래프를 보겠습니다.

· Sigmoid function Hypothesis
위는 바로 전에 말한 Sigmoid function, g(z) = 1 / (1 + e^(-z))를 표현한 그래프입니다. 식에서 z -> ∞일 때 g(z)는 1로 수렴하며 z -> -∞일 때 g(z)는 0으로 수렴합니다. 또한 정확히 표시되진 않았지만 위 그래프에서 특정 데이터가 Pass인지 Fail인지를 구분하는 경계는 0.5이며, 이 경계를 Decision boundary라고 합니다. 그렇다면 Logistic Regression에서 Hypothesis를 텐서플로우에서 어떻게 구현하는지 간단한 코드를 보며 살펴보겠습니다.

Linear Regression에서 배운 H(x)를 z = tf.matmul(X, W) + b로 표현했을 때 hypothesis는 tf.math.sigmoid() 메서드를 이용하여 쉽게 표현할 수 있습니다. 이 sigmoid() 메서드를 풀어쓴 것이 아래의 tf.math.divide(...)입니다. 물론 모든 sigmoid function이 위 그래프의 모양을 갖는 것은 아닙니다. 아래의 그래프를 보겠습니다.

먼저 왼쪽의 그래프는 Decisioin boundary가 검은색 실선으로 표시되어있습니다. w가 행 백터 [-3, 1, 1]이라고 했을 때(위 그림에서 x0는 생략되었지만 행렬곱을 위해 x0 = 1로 가정합니다.) 위 그래프의 Decisioin boundary는 x1 + x2 = 3입니다. 오른쪽 그래프에서 Decision boundary는 원형의 검은색 선으로 w가 행 벡터 [-1, 0, 0, 1, 1]이라고 했을 때 x1^2 + x2^2 = 1로 표현할 수 있습니다. 그렇다면 마지막으로 텐서플로우에서 Decision boundary를 활용하여 1, 0과 같은 결괏값을 얻는 코드를 보겠습니다. 코드는 tf.cast() 메서드를 활용하여 가설이 Decision boundary보다 큰 경우 1, 작은 경우 0을 반환하도록 작성되었습니다.

이번 포스트에서는 Logistic Regression(로지스틱 회귀)의 기본인 Classificatioin(분류), 로지스틱 회귀와 선형 회귀의 차이, 그리고 Sigmoid function과 로지스틱 회귀에서의 Hypothesis에 대해서 알아보았습니다.
다음 포스트에서는 이번 포스트에 이어 Logistic Regression의 Cost Function과 Optimizer(Gradient Descent)에 대해 살펴보겠습니다.
'AI > 모두를 위한 딥러닝' 카테고리의 다른 글
| 05-2. Logistic Regression(3) - Logistic Regression LAB (0) | 2020.04.17 |
|---|---|
| 05-1. Logistic Regression(2) (0) | 2020.04.13 |
| 04-1. Multi-variable Linear Regression LAB (2) | 2020.04.07 |
| 04. Multi-variable Linear Regression (0) | 2020.04.05 |
| 03-1. How to minimize cost - Gradient descent LAB (3) | 2020.04.04 |