2020. 6. 19. 13:15ㆍAI/모두를 위한 딥러닝
이 포스트는 모두를 위한 딥러닝 - Tensor Flow를 정리한 내용을 담았습니다.
누구나 이해할 수 있는 수준으로 설명하고자 하였으며 LAB의 코드는 TF2.0에 맞추어 재작성되었습니다.
이번 포스트에서는 딥 네트워크에서 Overfitting을 피하는 방법인 Dropout과 모델을 나누어 학습한 뒤 결과를 합쳐 예측하는 방법인 앙상블에 대해 알아보겠습니다.
먼저 Overfitting에 대해 간단히 복습해보겠습니다. 이전 포스트에서 우리는 이미 Overfitting에 대해 배운 적이 있습니다. Overfitting이란 Training dataset에만 너무 딱 들어맞아 전체 dataset의 측면에서 봤을 때는 적합하지 않은 모델입니다. 사실 Overfitting에 대한 설명은 아래 그림을 보면 직관적으로 이해할 수 있습니다. 오른쪽이 Overfitting 된 모델로써 Training dataset에만 딱 들어맞도록 구부러져 이후 전체 데이터에 대해서는 왼쪽 모델에 비해 대표성을 나타내지 못합니다.
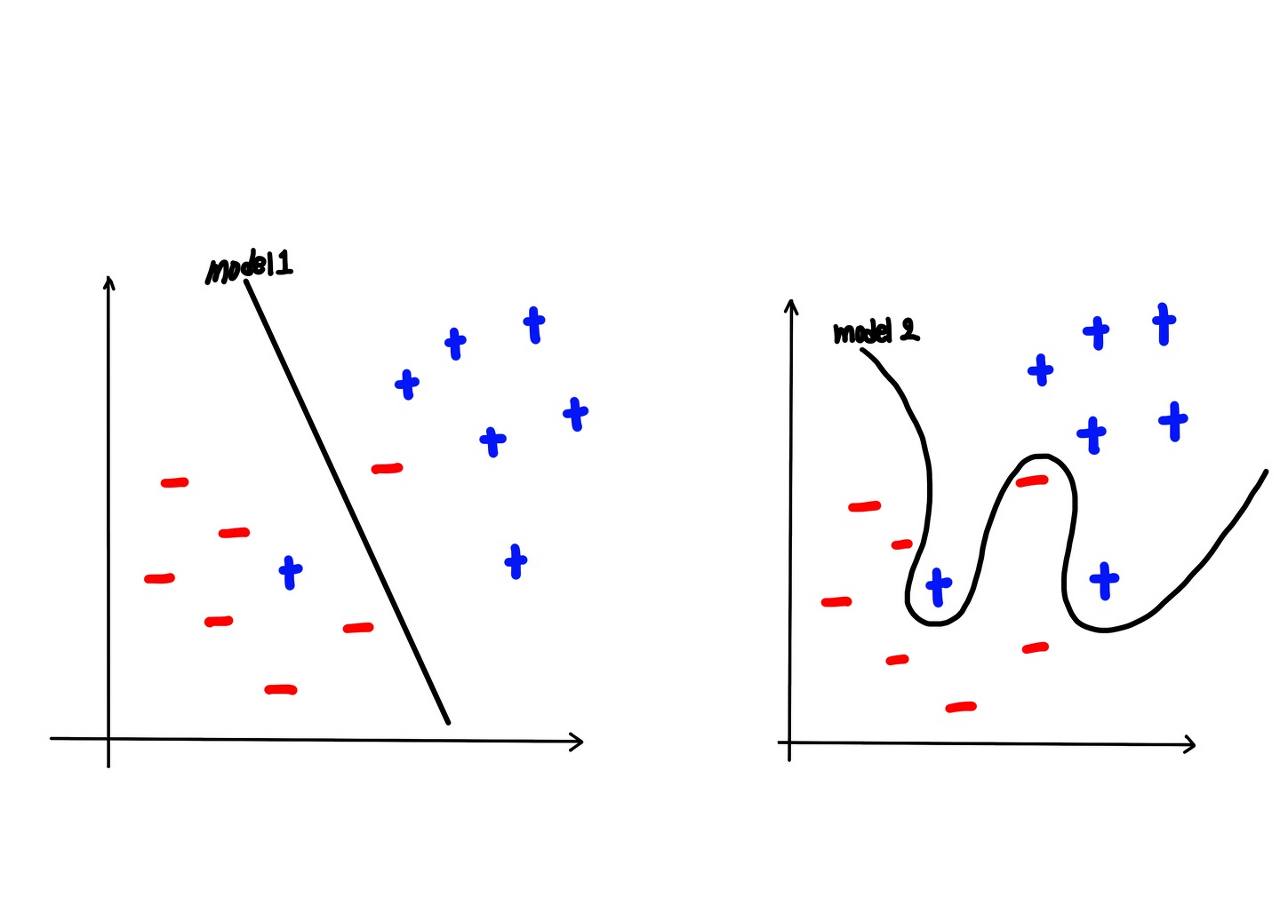

이러한 문제를 가진 Overfitting을 피하기 위해서는 어떤 방법들이 있을까요?
첫 번째는 Training data를 늘리는 것입니다. 이에 대해 07-2. Model evaluation: Training and test data sets에서 Dataset을 Training / Validation / Test set, 세 분류로 나누어 학습하는 방법에 대해서도 일전에 소개한 적이 있습니다. 직관적으로 Training dataset을 늘리면 전체 dataset와 비슷해질 것이며 즉 전체 dataset에 대해 일반성을 띌 수 있을 것입니다. 당연한 말이지만 전체 dataset에 대해 학습할 경우 Overfitting에 대해 생각하지 않아도 되기 때문에, Overfitting이 발생할 경우 Training dataset을 늘리는 것은 효과적일 수 있습니다. 물론 효율성과 속도 측면에서 어느 정도까지 Training dataset을 늘리는지에 대해서는 시행착오가 필요할 것입니다.
두 번째는 feature의 수를 줄이는 것입니다. 중복된 feature를 삭제하거나 중요한 feature만을 선택하여 학습하는 방법으로 Overfitting을 피할 수 있습니다. 이 과정은 딥러닝에서는 Dropout을 통해 feature를 자동으로 구현되기 때문에 직접 feature를 줄이는 것은 신경 쓰지 않으셔도 됩니다.
세 번째는 Regularization(정규화)입니다. 이전에 알아본 L2 Regularization(cost function에 λ*(∑W^2)를 더하여 구현)을 통해 weight이 너무 큰 값을 갖지 못하도록 제한하여 Overfitting을 피했습니다. L2 Regularization에서 lambda(λ)는 weight의 비율을 얼마나 반영할지를 결정하는 값으로 regularization strength로도 불립니다. 실제 뒤에 나올 dropout()의 인수 rate는 L2 Regularization의 lambda(λ)와 비슷할 역할을 합니다.
이제 딥러닝에서 Overfitting을 피하는 새로운 방법인 Dropout에 대해 알아보겠습니다. Dropout은 전체 weight으로 학습하는 것이 아니라, 임의로 몇몇의 weight을 0으로 만들어(반영하지 않고) weight 중 일부만으로 학습하는 방법입니다. 그림으로 보면 직관적으로 이해하기 쉬울 것이므로 아래 그림을 보겠습니다. standard neural network(좌)에서는 레이어의 모든 노드들끼리 이어져있는 모습을 볼 수 있습니다. 일반적인 경우로 모든 weight에 대해 학습하고 있습니다. 하지만 오른쪽의 Dropout모델을 보면 레이어의 몇몇 뉴런들은 학습에 관여하지 않는데, 이는 해당 뉴런의 weight을 잠시 0으로 만들었기 때문입니다. 헷갈리면 안 되는 것은 학습 시에만 임의의 뉴런의 weight을 0으로 두고 학습하였을 뿐 임의로 선택하기 때문에 다음 학습 시에는 다른 뉴런의 weight이 0이 될 수 있습니다. 따라서 선택된 뉴런들의 weight을 0으로 만드는 것이 아니라 weight을 0으로 가정하고 학습한다는 것을 인지해야 합니다.
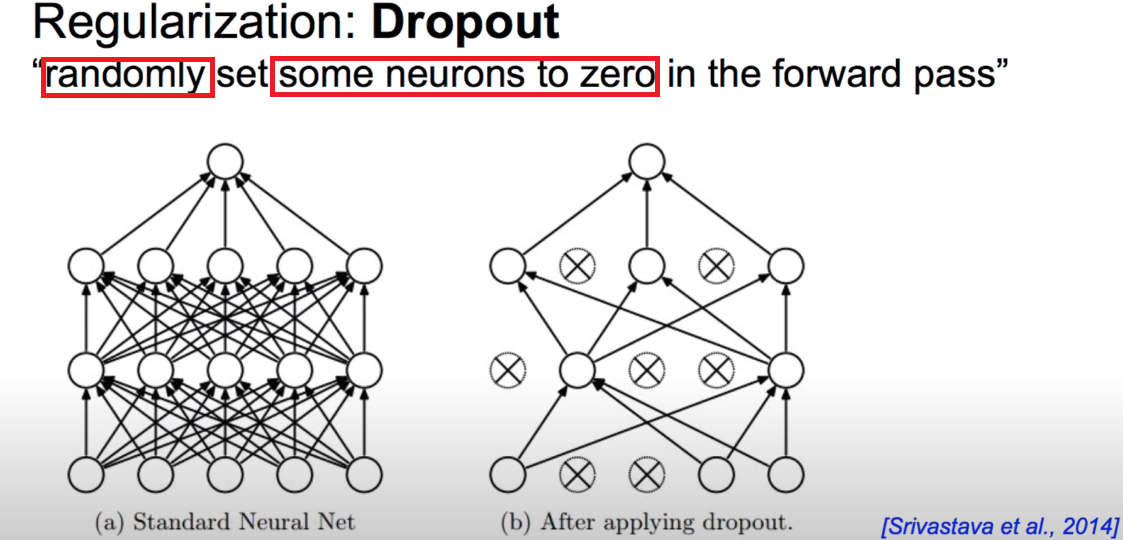
"Randomly(임의, 무작위로) set some neurons to zero(몇몇의 뉴런을 0으로 정한다)"에 대해 예시를 들어 살펴보겠습니다. 아래는 Dropout을 적용한 모델로, Output Layer 직전의 Hidden Layer을 오른쪽에 표현해보았습니다. Layer의 뉴런들의 데이터와 Output을 미루어보아 해당 모델은 고양이에 대한 특징들로 사진을 보고 고양이인지를 판단하는 뉴럴 네트워크로 보입니다. Hidden Layer의 뉴런들은 각각 귀가 있는지, 꼬리가 있는지, 털이 있는지, 발톱이 있는지, 장난스러운 표정을 가지고 있는지로 사진을 판단합니다. 이제 우리는 이들 중 귀가 있는지, 털이 있는지, 장난스러운 표정을 가지고 있는지로만 사진을 판단한다고 가정해보겠습니다. 이처럼 Dropout 하여 모델을 학습시켰을 때, 우리는 전체 뉴런들을 가지고 학습시켰을 때 보다 더 좋은 결과를 얻을 수도 있습니다. 실제로 오른쪽의 고양이 사진을 보면 사진에서는 꼬리와 발톱의 유무는 판단하기 쉽지 않습니다. 하지만 귀가 있는지, 털이 있는지, 장난스러운 표정을 짓는지에 대해서는 판단하기 쉽습니다. 이처럼 충분할 만큼의 뉴런들을 임의로 선택하며 반복적으로 학습하여 나온 결과를 평균해보면 전체 뉴런들에 대해서 학습했을 때 보다 균형 잡히고 정확도가 높은 결과를 얻을 수 있습니다. 또 다른 방법으로 생각해보면 아래의 경우는 너무 많은 특징들에 대해 사진을 판단하여 사진이 고양이인지 아닌지를 판단하는 것이 힘들었을 수도 있습니다. "사공이 많으면 배가 산으로 간다"는 속담처럼 때로는 딥러닝에서 모든 경우를 고려하고 모든 확률과 특징을 적용하는 것이 오히려 해가 될 수도 있다는 점을 생각하는 것은 앞으로의 딥러닝 공부에 큰 이점이 될 것 같습니다.

TF2.X에서는 tf.nn.dropout() 혹은 케라스에서 tf.keras.layers.Dropout()으로 Dropout을 구현해놓았습니다. 메소드의 사용법에 대해서는 링크의 텐서플로우 공식 페이지 혹은 이후 포스팅될 LAB 포스트에서 확인해주시길 바랍니다. 다만 이번 포스트에서 한 가지 짚고 넘어갈 점은 .dropout()의 인수 rate입니다. 위의 Overfitting을 피하는 방법으로 Regularization을 소개하며 "뒤에 나올 dropout()의 인수 rate는 L2 Regularization의 lambda(λ)와 비슷할 역할을 합니다."와 같은 말을 한 적이 있습니다. rate는 0 ~ 1 사이의 값으로, 뉴런을 반영하는 정도입니다. 보통 rate = 0.5를 사용하며 rate = 0.7은 70%의 뉴런만 참여하고 나머지 30%의 뉴런은 잠시 쉰다(해당 뉴런의 weight를 잠시 0으로 둔다)는 의미입니다. 다만 이는 학습 시에만 적용되며 모델을 평가하는 경우에는 당연히 모든 뉴런들을 학습에 참여시켜야 합니다(rate = 1).
마지막으로 앙상블(Ensemble) 방법에 대해 살펴보겠습니다. 이는 주로 학습할 수 있는 장비가 많을 때 사용할 수 있는 방법으로 아래의 그림과 같이 다수의 독립적인 학습 모델(Learning model)을 만들어 따로따로 학습한 뒤 모델들을 모두 합쳐 한 번의 예측을 만드는 것입니다. 그림에서는 Training dataset을 #1, #2, #k로 나누었지만 사실 모두 같은 dataset을 사용해도 상관없습니다. 다만 학습 모델을 #1, #2, #k로 나누어 Training dataset을 학습하면 각 모델의 초기값도 서로 다르고 Dropout을 적용할 시 학습에 사용되는 뉴런들도 서로 다르기 때문에 결과도 조금씩 다를 것입니다. 이렇게 독립적으로 학습한 모델들을 모아 한번에 예측을 하면 Dropout때와 같이 균형 잡힌 결과를 얻을 수 있을 것이라 기대합니다. 실제로 Ensemble 방법을 이용하여 학습할 시 2 - 5%의 수준으로 예측률이 올라간다는 연구 결과가 있습니다.

이번 포스트에서는 Overfitting을 피하기 위해 고안된 방법인 Dropout과 앙상블(Ensemble)에 대해 살펴보았습니다. 두 방법을 아는 것도 중요하지만, 특히 알아두어야 할 점은 딥러닝에서 모델을 학습시킬 때 모든 것을 생각하는 것보다 때로는 몇몇은 배제한 채(Dropout), 혹은 예측 시스템을 별도로 여러 개 만들어(Ensemble) 학습하는 방법이 훨씬 균형 잡히고 효율적인 모델을 만들어 낸다는 점입니다.
'AI > 모두를 위한 딥러닝' 카테고리의 다른 글
| 11-1. ConvNet의 Conv 레이어 만들기 (0) | 2020.07.03 |
|---|---|
| 10-4. 레고처럼 네트워크 모듈을 마음껏 쌓아 보자 (0) | 2020.06.19 |
| 10-2. Weight 초기화 잘해보자 (0) | 2020.06.17 |
| 10-1. Sigmoid 보다 ReLU가 더 좋아 (0) | 2020.06.13 |
| 09-4. XOR 문제 keras로 풀어 Tensorboard로 확인 LAB (0) | 2020.06.13 |