2020. 4. 25. 00:00ㆍAI/모두를 위한 딥러닝
이 포스트는 모두를 위한 딥러닝 - Tensor Flow를 정리한 내용을 담았습니다.
누구나 이해할 수 있는 수준으로 설명하고자 하였으며 LAB의 코드는 TF2.0에 맞추어 재작성되었습니다.
우리는 저번 포스트에서 텐서플로우에서 Softmax classification 함수들을 구현해보았습니다. 이번 포스트에서는 동물의 특징들로 구성된 파일에서 데이터를 추출하여 이전 포스트와는 조금 다른 방법으로 softmax classification을 구현하는 방법을 알아보겠습니다. 따라서 이번 포스트에서 코드를 설명할 때는 저번 포스트와 비교하여 설명하고 같은 코드는 생략하겠습니다. 궁금하다면 06-2. Softmax classification LAB(1)을 참고해주시길 바랍니다. 아래는 코드 전문이며, 데이터 파일(. csv)은 강의 댓글에서 다운로드하실 수 있습니다.


먼저 line 4 - 11을 보겠습니다. 이전 포스트에서는 Training data set이 많지 않아 직접 x_data와 y_data를 작성했지만, 이번에는 x_data와 y_data가 각각 101X16, 101X1로 굉장히 크기 때문에 로드한 파일을 리스트 슬라이싱 기법을 통해 x_data와 y_data를 정했습니다. 코드를 보면 x_data는 모든 행에 대해 마지막 열을 제외한 모든 열을, y_data는 모든 행에 대해 마지막 열만을 선택하여 슬라이싱 한 것을 확인할 수 있습니다. line 13 - 33은 이전 포스트와는 다른 방법으로 작성되어있습니다.

line 13 - 16에서는 tf.one_hot()을 이용하여 Y_one_hot을 만들고, tf.reshape()를 통해 Y_one_hot의 크기를 101X7로 조정했습니다. 주석과 아래 손그림을 통해 코드에 대한 설명을 자세히 보실 수 있습니다.


line 18 - 24에서는 W와 b를 랜덤한 값으로 초기화하고, 이 값을 이용해 logits = tf.matmul(features, W) + b를 만들었습니다. 앞으로 쓰일 logits는 저번 포스트에서 [scores - softmax function - probailities]의 과정에서 scores로, tf.matmul(X, W) + b의 hypothesis의 기본적인 포맷을 말합니다. 우리는 이 logits를 line 26 - 33에서 tf.nn.softmax_cross_entropy_with_logits()에 넣어 cross_entropy 함수를 만들고 cost를 구할 수 있습니다. 저번 포스트에서는 cost를 구하기 위해 tf.reduce_sum(Y *...)의 복잡한 식을 사용했지만, 코드에서 볼 수 있듯이 tf.... _with_logits()의 함수를 이용해 값을 쉽게 구할 수 있습니다.


line 43 - 48의 prediction()은 tf.argmax()를 이용해 One-hot encoding 된 x_data, y_data를 비교하여 정확도를 반환하는 함수입니다. is_correct_prediction을 보면 tf.equal()에서 one-hot encoded x_data와 y_data를 one-hot encoding 해 둘을 비교하는데, 사실 우리는 이미 Y_one_hot을 위에서 구했기 때문에 이 값을 바로 이용하는 것이 좋아 보입니다. 하지만 is_correct_prediction = tf.equal(predict, labels)와 같이 작성하면 함수 입장에서는 labels에는 어떤 입력이 들어올지 모르기 때문에 다음과 같은 오류가 발생합니다.
InvalidArgumentError: cannot compute Equal as input #1(zero-based) was expected to be a int64 tensor but is a float tensor [Op:Equal] # input #1이 int64 텐서임을 예상했지만, float형의 텐서이므로 Equal을 계산할 수 없습니다.

line 50 - 59는 Epoch횟수에 따라 cost와 accuracy를 구하여 출력하는 코드입니다. 저번 포스트와는 조금 다른 점은 실행 속도를 빠르게 하기 위하여 EPOCHS가 0 혹은 100의 배수일 때만 cost와 accuracy를 계산하도록 설계되어 있습니다.

마지막으로 line 61 - 64에서는 학습이 완료된 후의 예측 데이터(prediction)와 실제 값(y_data.flatten())을 비교하여 값을 출력하고 있습니다. 코드에서 y_data.flatten()은 numpy.ndarray타입을 numpy.int32으로, 쉽게는 [[1], [0]]의 다차원 배열을 [1, 0]의 일차원 배열로 평평하게 펴주는 역할을 합니다.
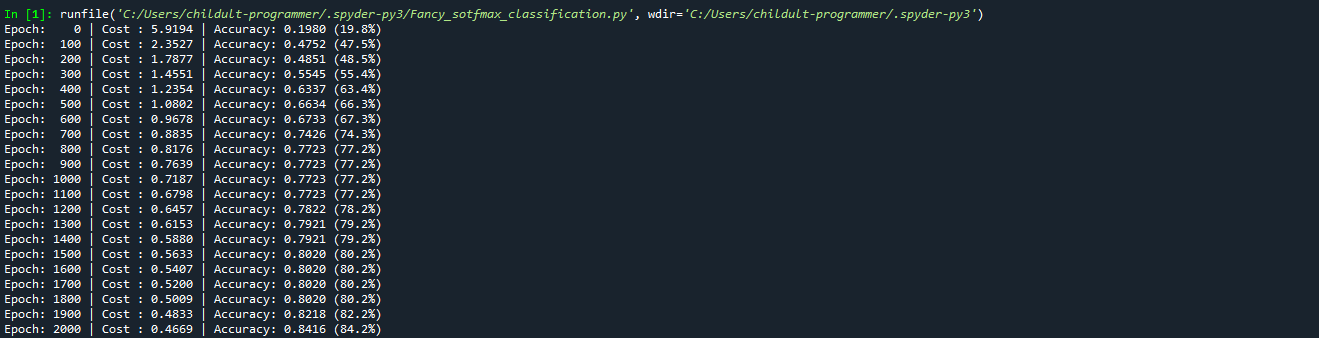
이제 코드에 대한 설명은 모두 끝났습니다. line 50에서 볼 수 있듯이 우리는 이번 코드를 작성해 Epoch가 늘어감에 따라 Cost값이 줄어들고 Accuracy가 늘어나며, 결과적으로 학습이 끝난 뒤에는 새로운 데이터(animal features)에 대해 다소 정확한 예측(y =? | 0 ~ 6)을 해주는 것을 기대합니다. 그럼 다음의 실행 결과를 보며 포스트를 마무리 짓겠습니다. 코드에서 W, b를 임의의 값으로 설정하였으므로 실행에 따라 결괏값은 항상 다릅니다.



'AI > 모두를 위한 딥러닝' 카테고리의 다른 글
| 07-2. Model evaluation: Training and test data sets (0) | 2020.05.04 |
|---|---|
| 07-1. Learning rate, Feature scailing, Overfitting, and Regularization (0) | 2020.04.30 |
| [공지] LAB 포스트 관련 공지사항 (0) | 2020.04.22 |
| 06-2. Softmax Classification LAB(1) (0) | 2020.04.21 |
| 06-1. Softmax classification (0) | 2020.04.19 |