2022. 2. 18. 16:00ㆍAI/ML
이 포스트는 허민석님의 유튜브 머신러닝 내용을 정리한 글입니다. 실습 코드는 도서 나의 첫 머신러닝/딥러닝에서 발췌해왔습니다. 실습 코드와 자료는 링크의 Github에서 볼 수 있습니다
이번 포스트에서는 MNIST 손글씨 데이터셋을 랜덤 포레스트 모델로 학습해보고, 동시에 의사결정 트리 모델을 학습하여 두 모델의 성능 차이를 시각화하여 비교해 보겠습니다. 추가로 이때까지 배운 kNN, SVM, Decision Tree 모델들을 앙상블 하여 보팅 하는 어그리게이팅 과정을 거쳐 더 좋은 예측 모델을 생성해보는 실습까지 진행해보겠습니다. 먼저 이전 포스트에서 살펴봤으나 다시 한번 랜덤 포레스트 모델에 대해 한 줄로 요약하자면 앙상블 기법을 사용하여 여러 의사결정 트리를 배깅하여 예측하는 모델입니다. 하나의 의사결정 트리로 데이터를 학습했을 시에는 과적합의 위험성이 매우 높으며 따라서 이를 보완한 랜덤 포레스트 모델이 학습 시 더 높은 정확도를 보일 것임을 예측하며 다음의 실습 과정을 보겠습니다.
MNIST는 숫자 0에서부터 9까지를 손글씨로 작성한 고정 이미지 크기의 데이터 셋으로, 총 60,000개의 학습 및 검증 데이터와 10,000개의 테스트 데이터로 이루어져있습니다. 하나의 이미지는 28x28의 고정된 크기로 2차원 배열에서 해당 픽셀에 손글씨가 있으면 0이 아닌 가중치를 부여하는 방식으로 2차원 행렬을 쭉 펴서 784(28x28) 개의 열을 가진 1차원 행렬로 변형되어 저장되어 있습니다. 따라서 mnist.train.image의 형태를 확인해보면 shape=[55000,784] 임을 확인할 수 있습니다. 하지만 이번 실습에서 사용할 MNIST 데이터셋은 실제 예측이 아닌 정확도 시각화 및 비교에 중점을 두고 있기 때문에 28x28이 아닌 8x8 형태의 1797개, 약 1800개의 데이터셋을 가진 load_digits()를 로딩하여 사용하겠습니다. 원래의 MNIST 데이터셋 전체를 로딩하고 싶다면 아래의 코드를 사용하셔도 무방합니다.
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784')
mnist.data.shape, mnist.target.shape # (70000, 784)
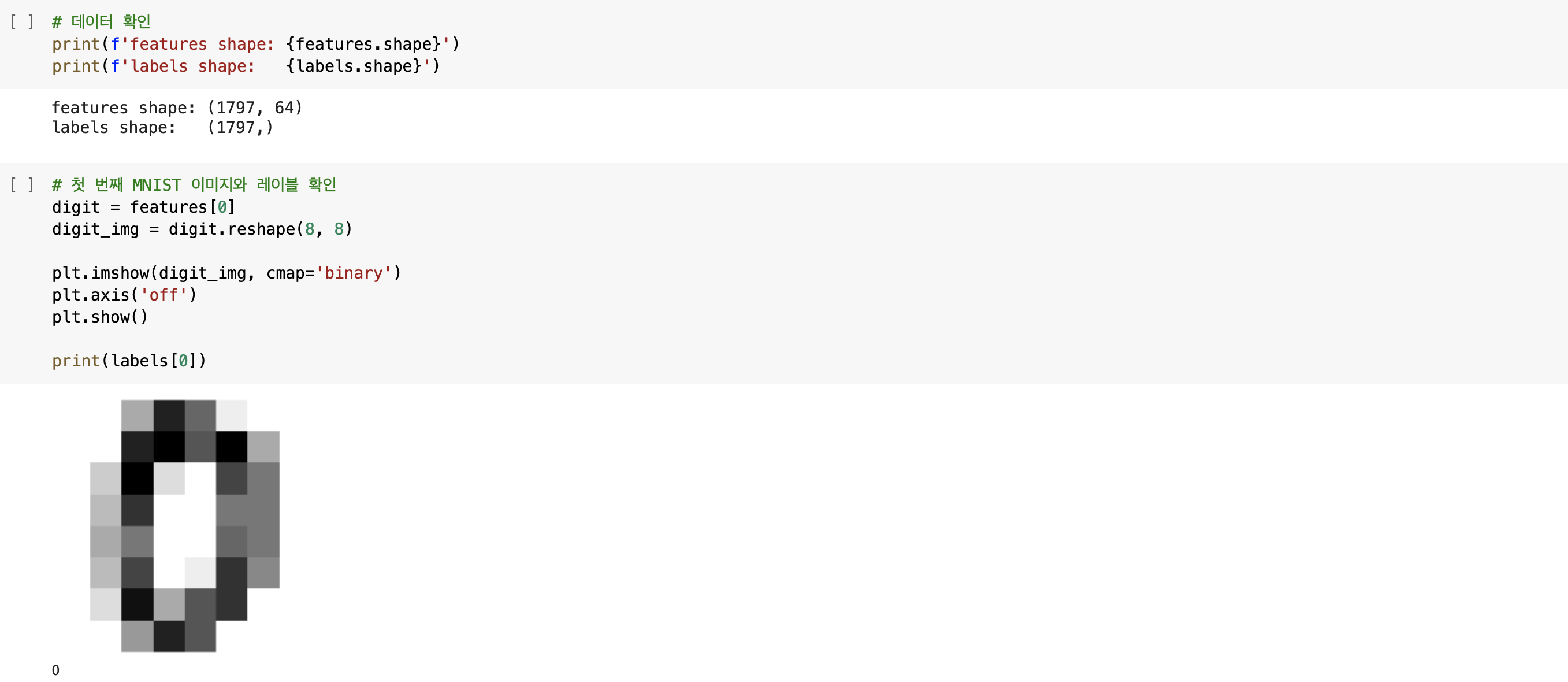
그렇다면 이번 실습에 사용할 MNIST 데이터 셋의 데이터 형태와 첫 번째 이미지 및 레이블을 직접 확인해보겠습니다. 첫 번째 이미지를 보면 다소 흐릿하지만 0임을 확인할 수 있으며 레이블 또한 0입니다. 이보다 중요한 점은 digit를 digit_img로 reshape 하는 과정인데, 원래의 MNIST 데이터셋에서는 이미지를 확인하기 위해 1차원으로 펴진 데이터를 2차원으로 표현하기 위해 reshape(28, 28)로 작성해야 하지만, 이번 MNIST 데이터셋의 이미지는 8x8로, 64개의 열을 가진 1차원 데이터로 펴져있기 때문에 복원할 때는 reshape(8, 8)로 작성해야 합니다. 바로 이러한 점을 확인하기 위해 바로 위에서 데이터 형태를 확인했으며, features shape: (1797, 64)에서 8x8의 이미지 크기임을 눈치채는 것이 앞으로의 코드 작성에 도움 될 것입니다.
이제 두 모델을 학습한 다음 이를 교차 검증할 함수를 만들겠습니다. 교차 검증 함수인 cross_validation()에서는 10회의 교차 검증을 통해(cv=10), 모델의 정확도를 측정한 평균값을 반환합니다. Decision Tree와 Random Forest 모델은 사이킷런에 구현되어 있으므로 별도의 하이퍼파라미터를 설정하지 않고 모델을 학습하여 교차 검증을 진행하겠습니다. 별도의 하이퍼파라미터를 설정하지 않은 이유는 Decision Tree의 과적합을 놔둔 채, 이를 보완하여 나온 Random Forest 모델과의 정확도 차이를 더욱 확연하게 보기 위함입니다.

이제 측정된 두 모델의 정확도를 판다스 형태로 시각화하겠습니다. cross_validation()에서 반환된 리스트를 담은 cv_list를 딕셔너리로 저장해 판다스의 데이터 프레임 형태로 만들어준 다음 plot()을 통해 그려보면 아래의 그래프를 볼 수 있습니다. 시각화하여 그래프를 그려보니, 두 모델의 확연한 성능 차이를 확인할 수 있습니다. 검증 횟수에 상관없이 모든 검증에서 Random Forest 모델이 Decision Tree 모델에 비해 정확도가 높았으며, Decision Tree 모델의 정확도가 다소 낮은 이유는 처음에 언급했듯 과적합이 원인임을 짐작해볼 수 있습니다. 실제로 정확도를 보면 Decision Tree는 0.822... 인 반면 Random Forest 모델은 0.948... 의 높은 정확도를 보이고 있습니다.


그렇다면 바로 다음으로 넘어가 보팅 앙상블 기법을 사용한 MNIST 손글씨 분류 실습을 해보겠습니다. MNIST 데이터셋은 위에서 이미 로딩해두었으므로 이번에는 앙상블 할 모델들(kNN, SVM, Decision Tree)을 임포트한 다음 이번에는 MNIST 데이터를 학습 데이터와 테스트 데이터로 분리하겠습니다. 이번 실습에서 살펴볼 점은 단일로 학습된 모델에 비해 앙상블한 모델의 예측 정확도가 더 향상되었는지를 살펴보는 것이 우선이므로, 먼저 단일 모델의 정확도를 측정해보겠습니다. 대신 이번에는 의사결정 트리를 학습 시 max_depth, max_features 등의 하이퍼파라미터를 설정해 과적합을 방지하고자 했으며, 모델들을 학습하고 예측하는 과정은 model.fit()과 model.predict()로 쉽게 구현할 수 있습니다.


단일 모델들의 정확도를 측정해보니 Decision Tree, kNN, SVM 모델 모두 0.8-0.9 사이의, 그렇게 높지는 않은 정확도임을 확인했습니다. 분명 이전 실습들에서 단일 모델들의 정확도는 낮지 않았는데, 이번 테스트에서 정확도가 낮게 나온 이유는 무엇이 있을까요? 먼저 1800개의 데이터를 또다시 학습 데이터와 테스트 데이터로 나누어 학습했으므로 학습 데이터가 충분하지 않았음이 하나의 이유로 예상되며 또한 학습 데이터의 특징에 따라 모델별 하이퍼파라미터를 조정해가며 다르게 설정하지 않고 보다 일반적인 하이퍼파라미터를 설정했는 것 또한 다른 이유일 수 있습니다. 하지만 이번 실습에서는 이 모델들을 앙상블 하여 보팅한 모델의 정확도를 보는 것이 중요하므로, 이러한 한계점은 인정하고 넘어가겠습니다. 앙상블한 모델에서 예측할때는 보팅 기법(어그리게이팅)을 사용합니다. 보팅은 소프트 보팅과 하드 보팅으로 나뉘며 사이킷런에서 voting classifier를 사용해 쉽게 구현할 수 있습니다. 만약 소프트 보팅을 직접 구현하고자 한다면, model.predict_proba()를 통해 가장 높은 분류값별 확률을 확인하여 구현할 수 있습니다. 실제로 SVM 모델의 첫 번째(label: 0)와 두 번째(label: 1) 데이터에 대한 분류값별 확률을 predcit_proba()를 통해 확인해보면 첫 번째 리스트에서는 0에 해당하는 9.99149483e-01이 최댓값으로 예측되었으나 두 번째 리스트에서는 9에 해당하는 3.29956631e-01이 최댓값으로 예측되었습니다. 이제 하드 보팅과 소프트 보팅을 직접 구현하여 정확도를 측정해보겠습니다. estimators에 학습된 세 모델을 입력한 다음 voting에 'hard'와 'soft'를 입력하면, 세 모델을 앙상블하여 voting 파라미터에 입력된 보팅 방식으로 학습된 모델을 얻을 수 있습니다. 사실 하드 보팅에 대해서도 만장일치일 때만 결정하는 Unanimous voting 기법과 다수결로 선택된 예측값이 전체의 50%를 넘어야 하는 Majority voting, 각각의 softmax에 대해 argmax 하여 다수결을 따르는 Plurality voting 기법 등이 있지만 voting='hard'로 설정하면 다수결의 원칙에 따라서만 decision 합니다. 하드 보팅과 소프트 보팅으로 구현한 모델의 정확도를 확인해보니 각각 0.933과 0.9로, 단일 모델들을 학습했을 때 보다 정확도가 확연히 높아졌음을 알 수 있습니다. 둘의 정확도를 더욱 시각화하여 보이기 위해 히스토그램 그래프로 표현하면 아래와 같은 결과를 얻을 수 있습니다.

하드 보팅의 정확도가 가장 높았으며 다음으로 소프트 보팅과 SVM, kNN 순으로 정확도가 높으며 Decision Tree의 정확도가 0.8로 가장 낮습니다.

이번 포스트에서는 축소화된 MNIST 데이터셋을 이용해 랜덤 포레스트 모델과 의사결정 트리의 정확도 차이를 확인했으며 kNN, SVM, Decision Tree 모델들을 단일로 학습했을 때와 이들을 보팅 앙상블 해 학습했을 때의 정확도 차이를 확인해봤습니다. 이로서 지도학습 머신러닝 분류 알고리즘에 대해 전반적으로 모두 살펴봤습니다. 다음 포스트부터는 비지도학습 중 하나인 군집화 알고리즘, k 평균 알고리즘에 대해 알아보겠습니다.
'AI > ML' 카테고리의 다른 글
| 앙상블(Ensemble)과 랜덤 포레스트(Random Forest) (0) | 2022.02.11 |
|---|---|
| 나이브 베이즈(Naive Bayes) 실습(3) - EDA, 영화 리뷰 긍정/부정 분류 (0) | 2022.02.01 |
| 나이브 베이즈(Naive Bayes) 실습(2) - 스팸 메일 분류 (0) | 2022.01.30 |
| 나이브 베이즈(Naive Bayes) 실습(1) - 붓꽃 분류 (0) | 2022.01.29 |
| 나이브 베이즈(Naive Bayes) (1) | 2022.01.24 |