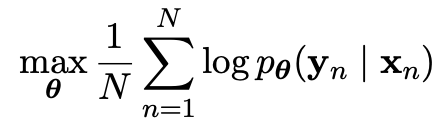2020. 11. 24. 04:20ㆍAI/딥러닝 논문 리뷰
Reference
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
참고 영상: 곽근봉님의 논문 리뷰 영상, 허민석님의 seq2seq + Attention model
참고 블로그: Jamie Kang's weblog on computing, gihub.io.
본 논문 리뷰는 작성자의 이해를 돕고자 작성자의 지식 범위 내에서 작성되었으며, 따라서 어려운 내용에 대한 상세한 설명이 다소 부족할 수 있습니다. 리뷰에 사용된 모든 사진은 논문에서 발췌해왔습니다.
· Abstract & Conclusion
전체적인 논문의 이해를 위해 서두의 Abstract와 마지막의 Conclusion을 묶었습니다.
논문은 새로운 NMT(Neural Machine Translation) 방법인 RNN Encoder-Decoder(앞으로는 seq2seq로 부름) 모델을 제안합니다.
RNN으로 만든 Encoder-Decoder구조와 새로운 Hidden Unit을 제안하며, 동시에 이전의 SMT(Statiscal Machine Translation)과 비교하여 새로운 가능성을 제안합니다.
논문은 또한 seq2seq 모델이 기존의 기계 번역 시스템에 쉽게 적용할 수 있는 점, 의미와 문법적인 내용을 담은 범용적인 Phrase Representation으로 활용할 수 있는 점에서 seq2seq 모델이 SMT 성능을 높일 수 있으며 더 나아가 SMT를 완전히 대체할 수 있는 가능성에 대해 말하고 있습니다.
따라서 이번 포스트에서는 seq2seq모델의 구조에 대해 알아보며 논문 내용에 더하여 Attention mechanism에 대해서도 알아보겠습니다.
· new Hidden state
Hidden state를 이해하기 위해서는 먼저 RNN에 대해 알고 있어야 합니다(논문 2.3절, Hidden Unit that Adaptively Remembers and Forgets). 이번 포스트에서는 RNN에 대해서는 따로 설명하지는 않지만, 필요하다면 이전 포스트 12-1.RNN / SimpleRNN, 12-2. RNN-LSTM레이어를 훑어보고 오시는 것을 추천드립니다.
저는 RNN의 구조를 한마디로 Hidden state를 통해 Input이 output으로 나오는 구조라고 설명하고 싶습니다. RNN의 핵심은 Hidden state에 있는데, 이번 논문에서는 새로운 형태의 Hidden state를 제안하고 있습니다. 아래는 새로운 Hidden state의 구조입니다.

그림에서는 두 형태의 h와 h̃이 나오는데, h를 이전의 Hidden state, h̃를 현재의 Hidden state을 의미합니다. 새로운 Gate인 r은 Reset Gate로 이전의 hidden state인 h를 얼마나 유지하고 반영할 것인지를 정하며 z는 Update Gate로 현재의 hidden state인 h̃을 얼마나 반영할 것인지를 정합니다. 위의 그림에서 이해하면 Reset Gate가 열려있을 수록, 즉 0에 가까울 수록 hidden state는 이전의 hidden state의 정보를 무시하고 새로운 input으로 업데이트합니다. r과 z에 대한 식은 아래 그림을 보며 설명하겠습니다. 먼저 Reset Gate입니다.

수식은 j번째 hidden state의 Reset Gate를 계산하 는 방식을 나타내는데, 이해를 위해 설명을 하자면, σ는 logistic sigmoid function, 활성화 함수를, [.]j는 j-th element of vector, 벡터의 j번째 요소를 의미합니다. Wr와 Ur는 weight을, x와 h⟨t−1⟩은 input과 이전 hidden state를 의미합니다. 이를 바탕으로 수식을 말로 풀어보면 Reset Gate는 input(x)에 weight(Wr)를 곱한 값과 이전 hidden state(h⟨t−1⟩)에 weight(Ur)를 곱한 값을 더해 활성화 함수인 sigmoid function에 넣어 구합니다. 이 때 주목할 점은 input에 곱하는 weight(Wr)와 hidden state에 곱하는 weight(Ur)이 다른 weight이라는 점입니다.

z는 r과 동일한 방식으로 계산하며, 새로 제안된 Hidden state를 구하는 수식은 아래로 표현됩니다.


새로운 hidden state의 수식을 예를 들어 설명하면 Update gate인 z의 값이 0.2일때, j번째 요소의 t번째 hidden state는 이전 state의 정보를 20% 넘겨주고 새로운 state의 정보를 80% 받는다고 해석할 수 있습니다. 참고로 위의 수식에서 ⊙는 element-wise product(Hadmard product), φ는 활성화 함수 tanh입니다. 이러한 방식으로 나온 hidden state들에 weight(V)를 곱해 Encoder의 output인 C(context vector)를 구할 수 있는데, 이는 RNN Encoder에서 다시 알아보겠습니다.
· Encoder-Decoder

위는 이번 논문의 핵심인 Encoder-Decoder 구조를 도식화한 그림입니다(논문 2.2절, RNN Encoder-Decoder). 먼저 Encoder에서는 input sequence X의 임베딩 벡터를 읽으면서 Hidden state를 update합니다. 예시를 들어 설명하면, "i love you"를 단어 단위로 고정된 크기의 임베딩 벡터로 만들어 입력 X로 넣습니다. 첫 번째 입력 X는 "i", 두 번째 입력 X는 "love", 세 번째 입력 X는 "you"가 임베딩된 벡터로 들어갈 것입니다. Encoder은 입력들을 받아 Hidden state를 update하며, input sequence의 마지막을 알리는 symbol인 EOS(End-Of-Sequence)를 받으면 hidden state는 전체 input sequence를 담은 벡터 c를 만듭니다. 총 N개의 input에 대해, 벡터 c를 만드는 식은 다음과 같습니다. c = tanh(V), V = weight, = h for N input sequence.
다음은 Decoder입니다. Decoder은 Encoder와는 반대로 주어진 Hidden state인

여기서 f는 non-linear activation function으로, 대표적으로 sigmoid와 tanh가 있습니다. linear activation function과 non-linear activation function에 대해서는 다음의 글에서 자세히 알 수 있습니다.
이제 모델이 Encoder-Decoder를 학습하는 과정이 남았습니다. 모델은 Encoder와 Decoder를 동시에 학습하며, 자세히는 input sequence data(x